
TL;DR:
- Transformers, a cornerstone of AI models, rely on self-attention but struggle with memory constraints when scaling up.
- UC Berkeley researchers introduce RingAttention, a game-changing approach to alleviate memory issues.
- RingAttention divides computations into blocks, allowing for seamless distribution and analysis across multiple devices.
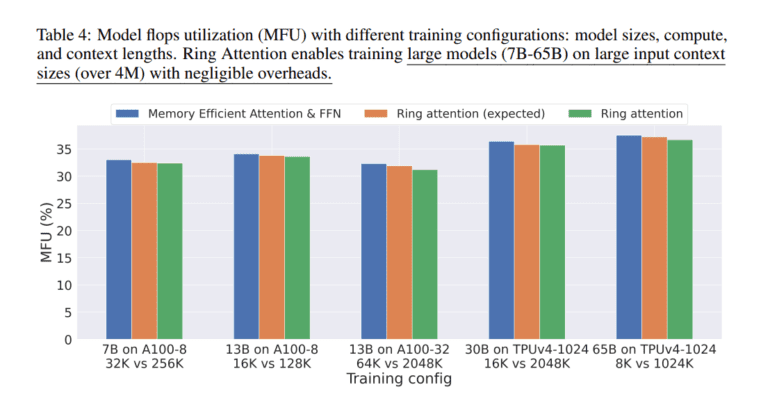
- It reduces memory constraints, enabling training on sequences over 500 times longer and even exceeding 100 million in length.
- Scalability depends on the number of devices and optimization efforts.
- Future work aims to maximize both sequence length and computational performance.
Main AI News:
In the ever-evolving landscape of artificial intelligence, the prominence of Transformers cannot be overstated. These deep learning model architectures have left an indelible mark, redefining the boundaries of AI capabilities. Among the many remarkable feats Transformers have achieved, their role in natural language processing and various machine learning tasks stands out prominently. At the heart of their prowess lies the self-attention mechanism, a crucial component that enables the model to assess the significance of different segments within input sequences. Comprising both an encoder and a decoder, Transformers have become indispensable tools in AI’s arsenal.
Nevertheless, as the scope and scale of AI applications grow, so do the challenges. Scaling up Transformers to accommodate longer input sequences has proven to be a formidable task. The inherent nature of self-attention, with its memory cost quadratically linked to input sequence length, poses a significant hurdle. Enter the groundbreaking innovation known as RingAttention, developed by the astute researchers at UC Berkeley, who have ingeniously addressed this conundrum.
The RingAttention approach stems from a simple yet profound observation. By breaking down self-attention and feedforward network computations into manageable blocks, it becomes possible to distribute sequences across multiple devices for more efficient analysis. Here’s how it works: the outer loop of computing blockwise attention is distributed among hosts, each responsible for managing its designated input block. Simultaneously, the inner loop conducts blockwise attention and feedforward operations specific to its assigned input block on all devices. Picture a conceptual ring formed by these host devices, where a copy of key-value blocks flows seamlessly from one device to the next. This synchronized transfer process ensures that block computations outpace block transfers, resulting in no additional overhead when compared to standard Transformers.
One of the most remarkable benefits of RingAttention is its ability to alleviate the memory constraints that individual devices typically face. Each device now requires memory resources proportionate only to the block size, regardless of the original input sequence’s length. This revolutionary approach empowers Transformers to train on sequences more than 500 times longer than previously possible with memory-efficient methods. Astonishingly, it even permits the training of sequences surpassing the 100-million mark without any compromises in attention to detail. The sky’s the limit with RingAttention, as it unlocks the potential for near-infinite context sizes, albeit at the expense of an increased number of devices corresponding to the sequence length.
It’s important to note that the research conducted thus far has primarily focused on evaluating the method’s effectiveness, without delving into large-scale training models. The scalability of context length remains dependent on the number of devices, highlighting the importance of optimization efforts. The researchers at UC Berkeley have concentrated their efforts on enhancing the low-level operations necessary for achieving optimal computational performance. In the future, their ambitions extend to mastering both maximum sequence length and maximum computer performance.
Conclusion:
RingAttention represents a significant breakthrough in AI, eliminating memory constraints for Transformers and opening doors to unprecedented possibilities. The market can expect a surge in applications, from massive video-audio-language models to enhanced code generation and advanced scientific data analysis. RingAttention’s impact on AI innovation is poised to reshape the industry landscape.