
TL;DR:
- Machine learning has revolutionized diverse fields but requires custom ML pipelines.
- Even simple ML pipelines can lead to problems when constructed or interpreted incorrectly.
- Data leakage is a significant threat to model reliability in supervised learning.
- Key strategies to prevent data leakage include strict data separation and rigorous model evaluation.
- Transparency in pipeline design and code accessibility enhances model confidence.
- ML faces challenges beyond data leakage, including biases and deployment complexities.
- Vigilance is urged to address potential issues in analytical methods.
Main AI News:
In the realm of machine learning (ML), a sweeping transformation has left an indelible mark on fields spanning medicine, physics, meteorology, and climate analysis. Through the potent tools of predictive modeling, decision support, and data interpretation, ML has ushered in a new era of insight. User-friendly software libraries, replete with a vast array of learning algorithms and data manipulation tools, have flattened the learning curve, fostering the proliferation of ML-based solutions. But amid this convenience, crafting a bespoke ML-driven data analysis pipeline remains an intricate endeavor, demanding meticulous customization across data handling, preprocessing, feature engineering, parameter tuning, and model selection.
It is incumbent upon us to recognize that even seemingly straightforward ML pipelines can wreak havoc when conceived or executed erroneously. Thus, a critical caveat must be underscored: the mere pursuit of repeatability within an ML pipeline does not ipso facto ensure the fidelity of its inferences. Addressing these concerns is the linchpin to enhancing the efficacy of applications and nurturing wider societal acceptance of ML methodologies.
This discourse zeroes in on the realm of supervised learning, a subdomain of ML where users grapple with data presented as feature-target pairs. While the proliferation of techniques and the advent of AutoML have democratized the crafting of high-caliber models, we must remain cognizant of the bounds of these advancements. Within the labyrinth of ML, a pernicious adversary lurks: data leakage. This stealthy menace exerts a profound influence on the reliability of models. Its detection and prevention are imperative to ensure the veracity and dependability of our models. Our text unearths this subject’s intricacies, offering up exhaustive examples, meticulous data leakage incident narratives, and prescriptive guidance for identification.
A collaborative endeavor by luminaries in the field unravels key facets common to most data leakage episodes. This consortium of researchers hails from esteemed institutions such as the Institute of Neuroscience and Medicine, Institute of Systems Neuroscience, Heinrich-Heine-University Düsseldorf, Max Planck School of Cognition, University Hospital Ulm, University Ulm, Principal Global Services (India), University College London, London, The Alan Turing Institute, European Lab for Learning & Intelligent Systems (ELLIS), and IIT Bombay. Their wisdom imparts strategic insights to forestall data leakage:
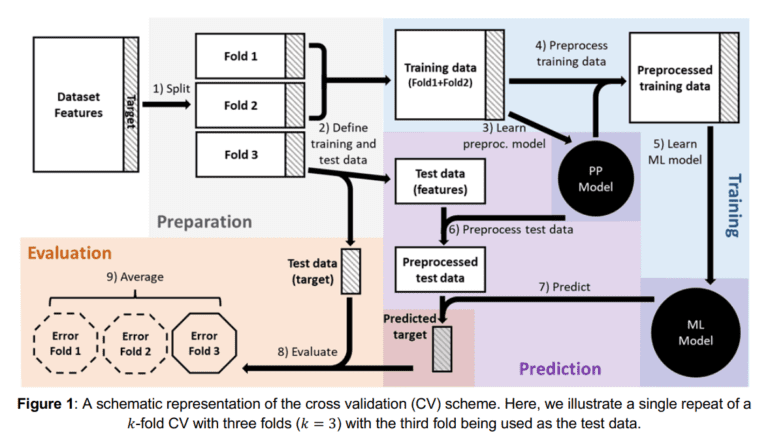
• Imposing a rigorous segregation of training and testing data.
• Harnessing the power of nested cross-validation for model assessment.
• Precisely delineating the ultimate objective of the ML pipeline.
• Scrutinizing the availability of features post-deployment with unwavering diligence.
The team’s clarion call resonates with the assertion that transparency in pipeline design, the sharing of techniques, and open access to code repositories can engender heightened confidence in a model’s generalizability. Furthermore, they advocate for the judicious utilization of existing, high-quality software and libraries, all while steadfastly upholding the integrity of the ML pipeline, prioritizing it over mere output or reproducibility.
In our acknowledgment of data leakage’s omnipresence, let us not be blind to the broader challenges that besiege the ML landscape. Dataset biases, deployment intricacies, and the relevance of benchmark data in real-world contexts constitute but a few of the formidable hurdles. While the scope of this discourse cannot encompass all these multifaceted issues, it serves as a clarion call to vigilance. Readers are exhorted to maintain an ever-watchful eye on potential pitfalls in their analytical methods.
Conclusion:
The importance of safeguarding machine learning pipelines, particularly against data leakage, cannot be overstated. As businesses increasingly rely on ML for decision-making and innovation, understanding the pitfalls and strategies outlined in this text is crucial. Maintaining transparency and vigilance in the ML process is not only a best practice but a competitive advantage in a market driven by data-driven insights and intelligent automation.