
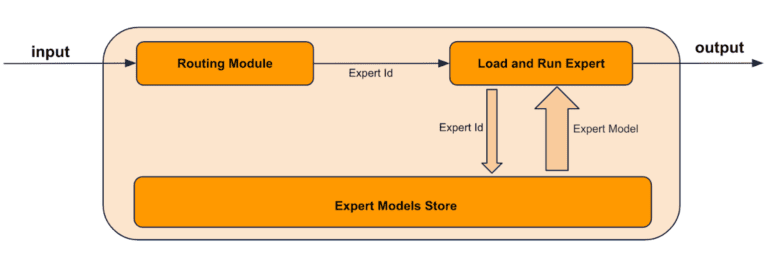
- Samba-CoE v0.3 by SambaNova redefines AI efficiency with advanced routing capabilities.
- It surpasses competitors on the OpenLLM Leaderboard, showcasing superior handling of complex queries.
- The model introduces a new routing mechanism based on uncertainty quantification for improved accuracy.
- Powered by the intfloat/e5-mistral-7b-instruct text embedding model, it excels on the MTEB benchmark.
- Incorporating k-NN classifiers with an entropy-based uncertainty measurement enhances routing accuracy.
- Limitations include support primarily for single-turn conversations and a lack of multilingual capability.
Main AI News:
In the dynamic realm of artificial intelligence, SambaNova’s latest offering, Samba-CoE v0.3, emerges as a pivotal advancement in optimizing the efficiency and efficacy of machine learning models. Outperforming competitors such as DBRX Instruct 132B and Grok-1 314B within the OpenLLM Leaderboard, this iteration of the Composition of Experts (CoE) system exemplifies unparalleled proficiency in managing intricate queries.
Central to the prowess of Samba-CoE v0.3 is its refined routing mechanism, meticulously crafted to streamline user queries towards the most suitable expert system within its framework. Building upon the foundational principles of predecessors Samba-CoE v0.1 and v0.2, which relied on an embedding router across five experts, this latest iteration introduces a novel paradigm in routing optimization.
A standout feature of Samba-CoE v0.3 is its enhanced router quality, achieved through the strategic integration of uncertainty quantification. This advancement empowers the system to leverage a robust base language model (LLM) when router confidence fluctuates, ensuring unwavering accuracy and reliability even in uncertain scenarios. Such capabilities are indispensable for systems tasked with managing diverse tasks without compromising output quality.
Driving Samba-CoE v0.3 forward is the cutting-edge text embedding model intfloat/e5-mistral-7b-instruct, lauded for its exceptional performance on the MTEB benchmark. Augmented by k-NN classifiers fortified with an entropy-based uncertainty measurement technique, the development team has further fortified the router’s capabilities. This strategic enhancement equips the router to not only pinpoint the most suitable expert for a query but also deftly navigate out-of-distribution prompts and training data noise.
While Samba-CoE v0.3 showcases remarkable strengths, it’s crucial to acknowledge its inherent limitations. Tailored primarily for single-turn conversations, its efficacy may diminish in multi-turn exchanges. Additionally, the model’s limited expert pool and absence of a dedicated coding expert may impose constraints on its utility in specialized tasks. Furthermore, its support for only one language could pose challenges for multilingual applications.
Nevertheless, Samba-CoE v0.3 remains a pioneering exemplar of seamlessly integrating smaller expert systems into a cohesive, efficient model. This approach not only amplifies processing efficiency but also mitigates the computational overhead associated with large-scale AI models.
Conclusion:
Samba-CoE v0.3 represents a significant advancement in AI efficiency, offering unparalleled capabilities in handling complex queries. Its innovative routing mechanism and integration of uncertainty quantification ensure consistent accuracy and reliability, setting a new standard for AI models. This development signifies a shift towards more efficient and scalable AI solutions, likely to impact the market by fostering greater adoption of advanced AI technologies.