
TL;DR:
- Alibaba’s SCEdit introduces a groundbreaking framework for image synthesis.
- SCEdit allows for high-quality image generation with precise control over the process.
- It outperforms existing methods in terms of efficiency and flexibility.
- Key components include SC-Tuner and CSC-Tuner for skip connection editing.
- SCEdit excels in text-to-image generation and controllable image synthesis tasks.
- Comparative analyses show lower FID scores and reduced memory consumption.
Main AI News:
In a recent publication by the Alibaba research team, a groundbreaking framework named SCEdit has emerged, promising to revolutionize image diffusion models with its exceptional skip connection tuning capabilities. The central challenge it addresses is the quest for a method that not only produces top-tier images but also grants meticulous control over the synthesis process, while accommodating a wide range of conditional inputs. While existing methods like ControlNet and T2I-Adapter have made strides in this domain, they still possess inherent limitations, necessitating the exploration of fresh approaches.
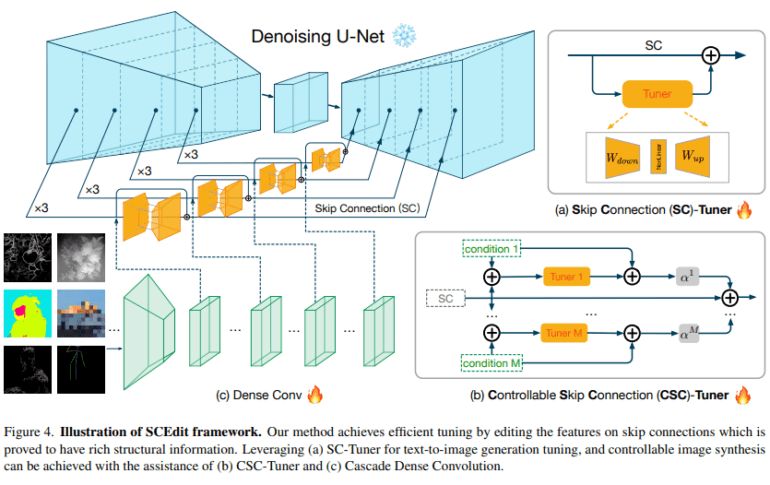
In the realm of image synthesis, the pursuit of controllability often grapples with efficiency and adaptability. Enter SCEdit, a game-changing framework that has been meticulously designed for the efficient editing of skip connections in image generation. At its core lie two innovative modules, SC-Tuner and CSC-Tuner, which facilitate the direct manipulation of latent features within these skip connections. What sets SCEdit apart from traditional methods is its lightweight and plug-and-play nature, seamlessly integrating with a variety of conditional inputs.
Diving deep into the methodology of SCEdit, we uncover its core components – SC-Tuner and CSC-Tuner. SC-Tuner draws inspiration from efficient tuning paradigms, showcasing its effectiveness across a spectrum of tuning operations, including LoRA OP, Adapter OP, and Prefix OP. This mathematical formulation combines a tuning operation (Tuner OP) with a residual connection, offering precise adjustments to skip connections. The extension to CSC-Tuner takes flexibility to new heights by incorporating additional conditional information, accommodating single and multiple conditions seamlessly.
The real efficiency of SCEdit shines when applied to text-to-image generation and controllable image synthesis tasks. Leveraging SC-Tuner for text-to-image generation and CSC-Tuner for controllable image synthesis, SCEdit demonstrates remarkable superiority in terms of both flexibility and efficiency. Experimental analyses encompass various aspects, from canny edge and depth to semantic segmentation and beyond. Comparative assessments against state-of-the-art methods, including ControlNet, T2I-Adapter, and ControlLoRA, unequivocally demonstrate SCEdit’s prowess in achieving lower Frechet Inception Distance (FID) scores, all while operating with significantly fewer parameters. This reduction in parameters translates into a substantial decrease in memory consumption and accelerated training times.
Conclusion:
SCEdit’s innovative approach to image synthesis and skip connection tuning represents a significant leap forward in the market. Its ability to generate high-quality images with precise control, while maintaining efficiency and flexibility, makes it a game-changer. This technology has the potential to reshape industries that rely on image generation, from e-commerce to entertainment, by streamlining the process and reducing resource consumption.