
TL;DR:
- MetaAI and UC Berkeley present SeamlessM4T, a groundbreaking multilingual and multitask model.
- SeamlessM4T facilitates translation and transcription across speech and text, supporting up to 100 languages.
- It addresses the limitations of previous systems by leveraging self-supervised speech learning and parallel data mining.
- Robustness tests show significant enhancements in performance, even against background noise and varying speakers.
- The model bridges the gap between high and low-resource languages, enabling more inclusive and connected communication.
- Researchers acknowledge challenges in translating slang and proper nouns, signaling future improvements.
Main AI News:
In an increasingly interconnected world, the power of multilingualism transcends mere communication—it forges connections, fosters comprehension, and unlocks gateways to a myriad of opportunities. Proficiency in multiple languages not only unveils the intricate tapestry of linguistics but also deepens insight into the art of expression and cognition. In an era defined by global interaction, the imperative to bridge the gap between human and artificial intelligence becomes all the more pronounced.
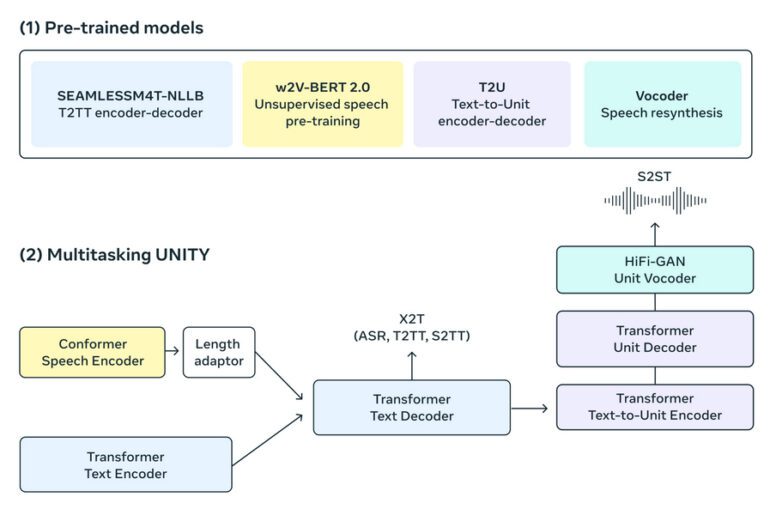
In a remarkable collaborative endeavor, scholars from MetaAI and UC Berkeley have unveiled a foundational marvel: SeamlessM4T, an exceptional multilingual and multitask model seamlessly facilitating translation and transcription across both speech and text domains. Aptly named, the acronym “M4T” signifies “Massively Multilingual and Multimodal Machine Translation.” This visionary AI model encompasses an extensive array of capabilities, including speech-to-text, speech-to-speech, text-to-speech, and text-to-text translations, alongside automated speech recognition, spanning an impressive repertoire of 100 languages.
Remember Babel Fish, the online translation tool? It’s a familiar name, but let’s delve into its limitations. Babel Fish operates as a speech-to-speech translation system, yet prevailing incarnations of such systems predominantly cater to high-resource languages such as English, Spanish, and French, inadvertently relegating numerous low-resource languages to the sidelines. Primarily facilitating translations from English to other tongues, these systems are unbalanced in their linguistic exchange. Their reliance on cascading subsystems undermines their overall efficacy, falling short of the performance benchmark set by their cascade counterparts.
Enter a groundbreaking solution: leveraging a staggering 1 million hours of open speech audio data, researchers harnessed self-supervised learning techniques to unlock the potential of SeamlessM4T. This innovative approach resulted in a multimodal corpus boasting impeccably aligned speech translations, spanning an astonishing 470,000 hours. Robustness tests, simulating various background noises and distinct speakers, showcased a remarkable 38% and 49% enhancement in performance, respectively.
Researchers diligently ensured the integrity of their system by conducting systematic evaluations at every juncture of their workflow, thus ensuring reliability and resilience. Their methodology embraced parallel data mining, a departure from conventional closed data practices. By encapsulating sentences from diverse languages within a standardized embedding space and subsequently identifying parallel instances through similarity metrics, the researchers revolutionized the model’s underpinnings.
The culmination of these efforts materializes in an all-encompassing model capable of navigating the intricate landscape of speech and text translation. This endeavor lays the bedrock for the forthcoming generation of on-device and on-demand multimodal translation solutions. The researchers underscore that an approach rooted in this philosophy directly addresses the needs of nearly half the global populace, harmonizing high and low-resource languages into a cohesive whole, ultimately propelling the world toward an unprecedented era of interconnectedness.
Acknowledging the model’s prowess, researchers candidly admit that refining the performance of SeamlessM4T with regard to translating slang and proper nouns across varied linguistic resource levels remains a challenge. This candid introspection underscores their commitment to crafting a more inclusive conversational experience—one that seamlessly adapts to colloquialisms and native expressions.
Conclusion:
In the realm of language technology, the introduction of SeamlessM4T marks a transformative stride. This cutting-edge model not only enables seamless translation and transcription but also addresses the long-standing limitations of existing systems. Its ability to handle diverse languages and adapt to various linguistic nuances ushers in a new era of global communication. This innovation holds the potential to reshape the market landscape by catering to a wider range of languages and bridging linguistic gaps, thus meeting the evolving demands of an interconnected world.