
TL;DR:
- Seoul National University introduces LAMA, a game-changing AI method for efficient robot control.
- LAMA eliminates the need for extensive scenario-specific training in robotics.
- It optimizes a single policy for various input conditions, significantly reducing computation time.
- The policy adapts and maintains the quality of synthesized motions across different scenarios.
- LAMA reduces computation time from 6.32 minutes to just 0.15 seconds per input pair.
- In real-world applications, LAMA promises more responsive and adaptable robotic systems.
Main AI News:
Seoul National University researchers have addressed a pivotal challenge in the field of robotics with their latest breakthrough, Locomotion-Action-Manipulation (LAMA). In an era where robots must seamlessly navigate ever-changing environments, traditional control methods have proven inefficient and inflexible. These conventional approaches demand extensive training for specific scenarios, resulting in substantial computational overhead. LAMA, on the other hand, introduces a revolutionary single-policy solution that optimizes robot behavior for diverse input conditions, eliminating the need for scenario-specific training.
The heart of this groundbreaking method lies in a policy that adapts and generalizes its behavior, dramatically reducing computation time while enhancing its efficacy in controlling robots. Instead of laboriously training separate policies for distinct scenarios, LAMA excels in handling various input conditions, simplifying the training process and bolstering the efficiency of robotic controllers.
Notably, the research team rigorously tested the policy across a spectrum of input variations, including initial positions and target actions, affirming its robustness and adaptability. In a field where conventional approaches demand copious data collection and extensive training periods for each unique scenario, LAMA’s adaptability is a game-changer.
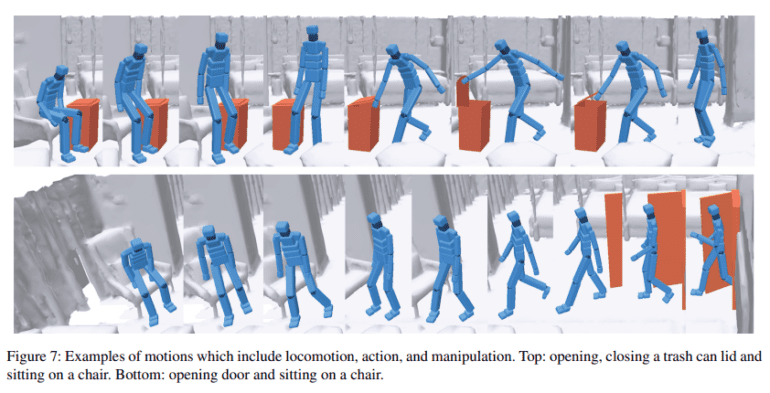
Moreover, the researchers scrutinized the physical plausibility of the synthesized motions derived from this policy. The results showcase not only the policy’s capacity to handle input variations effectively but also its ability to maintain the quality of synthesized motions. This ensures that a robot’s movements remain both realistic and physically sound across diverse scenarios.
Perhaps the most compelling advantage of LAMA is its significant reduction in computation time. Traditional robotics control methods entail labor-intensive training for each distinct scenario, a process that can be exceptionally time-consuming and resource-intensive. In stark contrast, LAMA’s pre-optimized policy for specific input conditions obviates the need for retraining, leading to a remarkable reduction in computation time. On average, it takes a mere 0.15 seconds for motion synthesis with the pre-optimized policy, compared to a staggering 6.32 minutes (equivalent to 379 seconds) when training from scratch for each scenario. This substantial disparity underscores the efficiency and time-saving potential of LAMA’s innovative approach.
Conclusion:
Seoul National University’s LAMA innovation signifies a significant leap in the field of robot control. Its single-policy approach, adaptability, and reduced computation time hold the potential to revolutionize the market by offering more efficient and responsive robotic systems, particularly in scenarios where rapid adaptation is crucial. This advancement aligns with the growing demand for automation solutions that optimize efficiency and adaptability in diverse real-world environments.