
- SF-LLaVA introduces a training-free Video LLM with a SlowFast design to improve video processing.
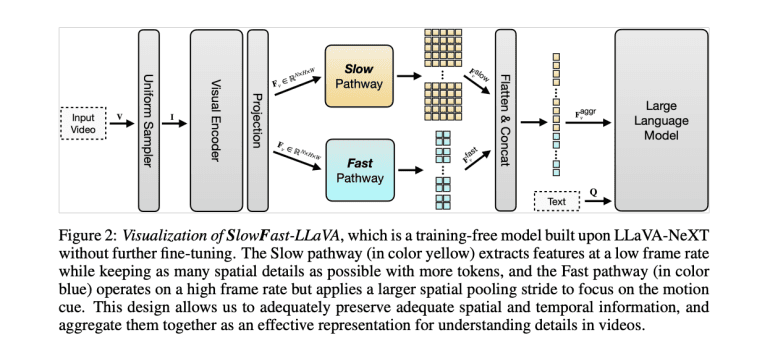
- The SlowFast architecture includes a Slow pathway for high-resolution, low-frame-rate feature extraction and a Fast pathway for low-resolution, high-frame-rate temporal modeling.
- The model avoids the need for additional fine-tuning, unlike many existing Video LLMs.
- SF-LLaVA has shown superior performance in video understanding tasks, including open-ended and multiple-choice VideoQA, and excels in temporal reasoning.
- It often outperforms other training-free methods and competes closely with supervised fine-tuning models.
- Despite occasional limitations in fine spatial detail, its ability to handle longer temporal contexts is a key strength.
Main AI News:
The emergence of video large language models (LLMs) has introduced a new era in processing video inputs and generating relevant responses to user commands. Yet, these models face significant obstacles, primarily due to the high computational and labeling costs associated with supervised fine-tuning (SFT) video datasets. Additionally, many existing Video LLMs struggle with key limitations: their ability to process extensive input frames is often insufficient, impeding the capture of detailed spatial and temporal content throughout videos. Furthermore, they lack effective temporal modeling, relying only on the LLM’s inherent capacity to model motion patterns without specialized video processing components.
To address these issues, researchers have explored various LLM approaches. Image LLMs like Flamingo, BLIP-2, and LLaVA have achieved success in visual-textual tasks, while Video LLMs such as Video-ChatGPT and Video-LLaVA have extended these capabilities to video processing. Despite these advancements, the need for expensive fine-tuning on large video datasets remains a challenge. Training-free alternatives like FreeVA and IG-VLM have emerged as cost-effective solutions, leveraging pre-trained Image LLMs without additional fine-tuning. However, these methods still face difficulties in processing longer videos and capturing intricate temporal dependencies, limiting their effectiveness with diverse video content.
Apple’s SF-LLaVA offers a groundbreaking solution by introducing a training-free Video LLM that tackles video processing challenges through its innovative SlowFast design. Inspired by successful two-stream networks for action recognition, SF-LLaVA captures both detailed spatial semantics and extensive temporal context without the need for additional fine-tuning. The model features a Slow pathway for low frame rate, high-resolution feature extraction, and a Fast pathway for high frame rate, aggressive spatial pooling. This dual-pathway architecture optimizes modeling capability and computational efficiency, allowing SF-LLaVA to process more video frames while preserving critical details. By integrating complementary features from slowly changing visual semantics and rapidly changing motion dynamics, SF-LLaVA provides a comprehensive understanding of videos and overcomes the limitations of previous methods.
The SlowFast-LLaVA (SF-LLaVA) model introduces a novel SlowFast architecture for training-free Video LLMs, effectively capturing both detailed spatial semantics and long-range temporal context without exceeding the token limits of conventional LLMs. The Slow pathway processes high-resolution but low-frame-rate features (e.g., 8 frames with 24×24 tokens each) to capture spatial details, while the Fast pathway handles low-resolution but high-frame-rate features (e.g., 64 frames with 4×4 tokens each) to model broader temporal contexts. This dual-pathway approach enables SF-LLaVA to maintain both spatial and temporal information, integrating them into a powerful representation for comprehensive video understanding without additional fine-tuning.
SF-LLaVA has demonstrated exceptional performance across various video understanding tasks, often outperforming state-of-the-art training-free methods and competing closely with SFT models. In open-ended VideoQA tasks, SF-LLaVA surpasses other training-free methods on all benchmarks, with improvements up to 5.7% on some datasets. For multiple-choice VideoQA, SF-LLaVA shows significant advantages, especially in complex long-form temporal reasoning tasks like EgoSchema, where it exceeds IG-VLM by 11.4% using a 7B LLM. In text generation tasks, SF-LLaVA-34B outperforms all training-free baselines on average and excels in temporal understanding. While it occasionally falls short in capturing fine spatial details compared to some methods, its SlowFast design efficiently covers longer temporal contexts, demonstrating superior performance in most tasks, particularly those requiring robust temporal reasoning.
Conclusion:
SF-LLaVA’s innovative SlowFast architecture represents a significant advancement in the field of video LLMs by effectively integrating spatial and temporal information without the need for additional fine-tuning. This model addresses key challenges in video processing, such as high computational costs and limitations in handling extended temporal contexts. For the market, SF-LLaVA’s efficiency in training-free video understanding positions it as a strong contender against traditional, fine-tuned models, potentially reducing the barriers to entry for advanced video analysis solutions. Its superior performance in various video tasks highlights its potential to set new standards in the industry and drive further innovation in training-free video processing technologies.