
- ShiftAddLLM revolutionizes LLM efficiency through post-training shift-and-add reparameterization, replacing traditional multiplications with hardware-friendly operations.
- It minimizes weight and activation reparameterization errors, significantly reducing memory usage and latency while maintaining or improving model accuracy.
- Automated bit allocation optimizes bit-widths for weights based on sensitivity to reparameterization, preventing accuracy loss while maximizing efficiency.
- Validated across various LLM families and tasks, ShiftAddLLM showcases substantial perplexity improvements and over 80% reductions in memory and energy consumption.
- Experimental results demonstrate superior performance compared to existing quantization methods, with significant reductions in perplexity scores and latency.
Main AI News:
In the realm of deploying large language models (LLMs) on resource-constrained devices, challenges abound. Their vast parameters and reliance on dense multiplication operations present significant hurdles, leading to high memory demands and latency bottlenecks. This, in turn, restricts their practical application in real-world scenarios. For example, models like GPT-3 demand immense computational resources, rendering them unsuitable for many edge and cloud environments. Overcoming these obstacles is paramount for advancing AI, as it would facilitate the efficient deployment of potent LLMs, thereby expanding their applicability and influence.
To address these challenges, various methods have been explored, including pruning, quantization, and attention optimization. While pruning techniques reduce model size by eliminating less significant parameters, they often sacrifice accuracy. Quantization, especially post-training quantization (PTQ), decreases the bit-width of weights and activations to alleviate memory and computation demands. However, existing PTQ methods necessitate significant retraining or result in accuracy degradation due to quantization errors. Moreover, these methods still heavily rely on costly multiplication operations, constraining their effectiveness in reducing latency and energy consumption.
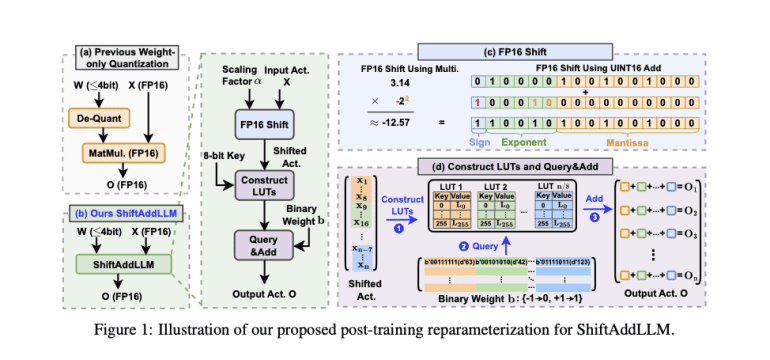
Enter ShiftAddLLM, a pioneering method devised by researchers from Google, Intel, and the Georgia Institute of Technology. This approach accelerates pre-trained LLMs through post-training shift-and-add reparameterization, replacing traditional multiplications with hardware-friendly shift and add operations. By quantizing weight matrices into binary matrices with group-wise scaling factors, ShiftAddLLM reparameterizes multiplications into shifts between activations and scaling factors, and queries and adds based on the binary matrices. This strategy mitigates the limitations of existing quantization techniques by minimizing both weight and activation reparameterization errors via a multi-objective optimization framework. The result? Substantial reductions in memory usage and latency, all while maintaining or enhancing model accuracy.
Employing a multi-objective optimization method, ShiftAddLLM aligns weight and output activation objectives to minimize overall reparameterization errors. The researchers have introduced an automated bit allocation strategy, optimizing the bit-widths for weights in each layer based on their sensitivity to reparameterization. This ensures that more sensitive layers receive higher-bit representations, averting accuracy loss while maximizing efficiency. Validated across five LLM families and eight tasks, ShiftAddLLM showcases average perplexity improvements of 5.6 and 22.7 points at comparable or lower latency compared to the best existing quantized LLMs. Additionally, it achieves over 80% reductions in memory and energy consumption.
Experimental results underscore the efficacy of ShiftAddLLM, with significant perplexity score enhancements across various models and tasks. For instance, compared to OPTQ, LUT-GEMM, and AWQ at 3 bits, ShiftAddLLM achieves perplexity reductions of 5.63, 38.47, and 5136.13, respectively. In 2-bit settings, where most baselines falter, ShiftAddLLM maintains low perplexity and records an average reduction of 22.74 perplexity points over the most competitive baseline, QuIP. Moreover, it demonstrates superior accuracy-latency trade-offs, with up to 103830.45 perplexity reduction and up to 60.1% latency reductions. The table below presents a comprehensive comparison of perplexity scores and latencies of various methods, underscoring ShiftAddLLM’s superior performance in both metrics.
Conclusion:
ShiftAddLLM’s innovative approach marks a significant breakthrough in deploying efficient large language models. Its ability to drastically reduce memory usage and latency while maintaining or enhancing accuracy has profound implications for the market, enabling the widespread adoption of powerful LLMs across resource-constrained devices and environments. This not only expands the applicability of AI technologies but also opens up new opportunities for businesses to leverage advanced language processing capabilities in various domains.