
- Sibyl, an AI framework, enhances large language models (LLMs) for complex reasoning tasks.
- Challenges addressed include error propagation and context management in real-world scenarios.
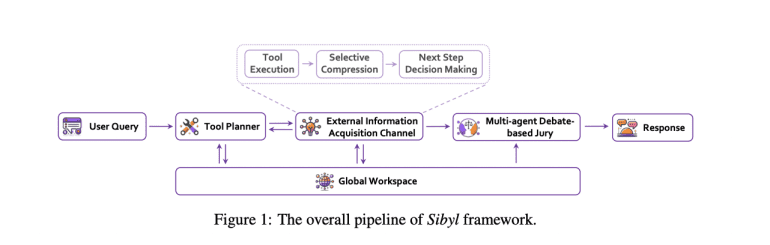
- Developed by Baichuan Inc. and Tianjin University, Sibyl integrates a tool planner, information acquisition channel, jury, and global workspace.
- Key innovation: external information channel for efficient data processing and extended reasoning.
- Functional programming principles ensure reusability and statelessness, simplifying architecture and maintenance.
- GAIA benchmark tests show Sibyl outperforms competitors in Level 2 and 3 scenarios with 34.55% accuracy.
- Sibyl’s design philosophy focuses on reducing complexity while improving long-term memory, planning, and error correction.
- Market implications: Sibyl sets a new standard for AI agents, promising enhanced problem-solving capabilities in complex domains.
Main AI News:
Advancements in large language models (LLMs) have revolutionized human-computer interaction, yet they face significant challenges in real-world scenarios that demand extensive reasoning abilities. LLM-based agents often struggle with managing lengthy reasoning chains, resulting in error propagation and decreased accuracy. The complexity of existing systems poses obstacles to practical deployment and scalability, especially concerning the management of long-context interactions and integration of diverse information sources. These challenges highlight the critical need for a streamlined approach that enhances reasoning capabilities while effectively managing contextual information, ensuring that LLMs can maintain focus on pertinent data without becoming overwhelmed by the volume of information.
Recent strides in AI have seen LLMs integrated into autonomous agents, marking a significant step towards achieving Artificial General Intelligence (AGI). These agents have shown promise across various domains such as mathematical problem-solving, coding, role-playing, and social simulations. However, their performance falters when confronted with the intricate challenges of real-world scenarios. This limitation underscores the necessity for further advancements in general-purpose LLM-based agents to effectively tackle complex problems and bridge the gap between specialized and truly versatile AI systems.
Introducing Sibyl, an innovative LLM-based agent framework developed by researchers from Baichuan Inc. and the College of Intelligence and Computing at Tianjin University. Sibyl is designed specifically to address complex reasoning tasks and features four key modules: a tool planner, an external information acquisition channel, a multi-agent debate-based jury, and a global workspace. The framework’s standout feature is its external information acquisition channel, which efficiently compresses and processes data using a custom representation language. This approach enables Sibyl to focus on relevant details while preserving context length, thus facilitating extended reasoning capabilities. Moreover, Sibyl’s architecture includes a global workspace for seamless information sharing and a jury mechanism for self-refinement prior to generating final responses.
Sibyl is underpinned by functional programming principles that prioritize reusability and statelessness. It employs QA functions instead of dialogue-based internal LLM inference requests, allowing for independent operation without the need for persistent states. This design simplifies the framework’s structure, enhances its flexibility, and facilitates easier debugging and maintenance. Experimental results from the GAIA benchmark test set demonstrate Sibyl’s state-of-the-art performance, particularly in challenging Level 2 and Level 3 scenarios. These results underscore Sibyl’s improved capability in solving complex reasoning tasks and its potential to advance LLM-based applications towards more deliberate, System-2 thinking.
Furthermore, Sibyl’s design philosophy emphasizes reducing complexity while enhancing LLM capabilities. It utilizes a human-oriented browser interface, preserving more context and depth in data access compared to traditional Retrieval Augmented Generation methods. By employing a stateless, reentrant QA function rather than dialogue-based interactions, Sibyl further simplifies its system architecture, thereby promoting easier maintenance and enhancement. The framework centralizes its functionalities around two primary tools: a web browser and Python environments, aligning the browser interface more closely with human interaction modes.
In addition to its innovative design, Sibyl focuses on enhancing capabilities related to long-term memory, planning, and error correction. It incorporates a global workspace shared by all modules, storing information with an incremental, state-based representation language that selectively compresses past events, thereby adding only relevant information increments. The framework also includes planning and self-correction mechanisms, summarizing tool outcomes and planning subsequent steps based on current progress assessments. The “Jury” mechanism, which utilizes a multi-agent debate format, enables self-critique and correction by efficiently leveraging information stored in the global workspace to refine responses and ensure accurate problem-solving.
Experimental results further validate Sibyl’s superior performance on the GAIA benchmark test set, particularly in challenging Level 2 and Level 3 scenarios. Sibyl outperformed other models, including GPT-4 with and without plugins, AutoGPT-4, AutoGen, and FRIDAY. On the test set, Sibyl achieved an overall accuracy of 34.55%, compared to 32.33% for AutoGen and 24.25% for FRIDAY. The performance gap widened in more complex scenarios, highlighting Sibyl’s enhanced ability to mitigate error propagation in complex reasoning processes.
Moreover, Sibyl demonstrated superior generalization capabilities, exhibiting a smaller decline in accuracy from validation to the test set (40.00% to 34.55%) compared to AutoGen (39.39% to 32.33%) and FRIDAY (34.55% to 24.25%). In terms of efficiency, Sibyl consistently outperformed humans in correctly solving problems, using significantly fewer steps across all difficulty levels. Despite its limitation to 20 reasoning steps, Sibyl demonstrated high reasoning efficiency, indicating strong capabilities to mitigate unnecessary reasoning and suppress error propagation. These findings underscore Sibyl’s potential to advance LLM-based agents towards more deliberate and efficient problem-solving in complex scenarios.
Conclusion:
Sibyl represents a significant advancement in AI technology, offering robust capabilities for handling complex reasoning tasks. Its innovative framework and superior performance on benchmarks position it as a frontrunner in enhancing AI agents’ effectiveness across diverse applications. As the market continues to demand more sophisticated AI solutions, Sibyl’s approach to integrating large language models with streamlined functionality marks a pivotal development towards achieving more intelligent and efficient AI systems.