
TL;DR:
- Soft MoE introduces a novel approach to sparse Transformers, resolving computational challenges.
- It replaces rigid routing with dynamic, weighted token amalgamation.
- Soft MoE adapts in real-time, offering stability and efficient routing.
- Batch effects during inference are eradicated, enhancing accuracy.
- Soft MoE outperforms ViT H/14 in training time and inference speed.
- A landmark solution for diverse industries, Soft MoE, reshapes Transformer capabilities.
Main AI News:
As the demand for advanced computational solutions surges, the realm of large-scale Transformers emerges as a dominant force. Nevertheless, the optimization of larger Transformers poses a conundrum, demanding substantial computational resources. Recent research illuminates a symbiotic relationship between model size and training data, emphasizing the necessity to scale both concurrently to maximize training compute resources. Enter sparse mixes of experts (MoEs), a promising alternative that upholds model scalability while mitigating the burdensome computational overhead. This innovation holds particular promise for diverse fields such as language processing, vision tasks, and multimodal applications, where activating specific token pathways is of paramount significance.
The crux of the challenge resides in the strategic activation of modules for each input token—a process akin to navigating a complex labyrinth. This challenge lies at the heart of sparse MoE Transformers, where traditional solutions like linear programs, reinforcement learning, and top-k expert-token pairings aim to solve this intricate optimization problem. Alas, these methods often necessitate auxiliary losses to strike a balance between expert utilization and minimizing unassigned tokens. The intricacy deepens when confronted with small inference batches, unique inputs, or transfer learning scenarios, potentially aggravating these issues in out-of-distribution contexts.
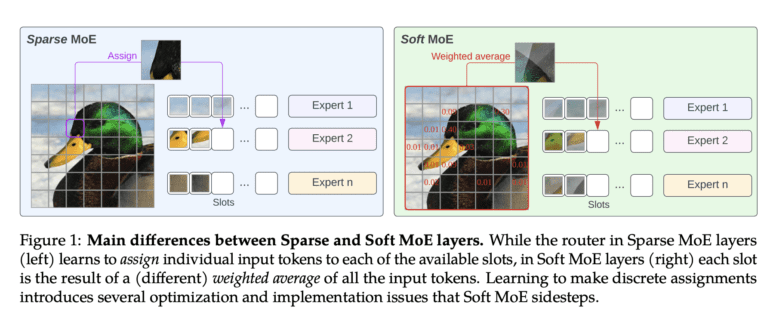
Recognizing these hurdles, visionary minds at Google DeepMind have crafted a groundbreaking solution: Soft MoE. Departing from the rigid, discrete assignment approach, Soft MoEs introduce a paradigm shift by amalgamating tokens through soft assignments. This dynamic process involves creating weighted averages of tokens, leveraging both token and expert qualities as guiding metrics. These weighted averages are then channeled through the pertinent expert, circumventing the pitfalls of discrete mechanisms that often mar the efficiency of sparse MoEs.
One salient advantage of Soft MoEs is their inherent ability to adapt and evolve during training. Unlike their fixed-routing counterparts, which might resemble random allocations, Soft MoEs recalibrate routing parameters for each input token in real-time. This agile adaptation mitigates issues associated with abrupt changes in discrete paths, thus instilling stability and resilience into the routing process. Additionally, the scalability of Soft MoE extends to encompass a multitude of experts, defying limitations that confine conventional methods.
A notable facet of Soft MoE’s prowess is its immunity to batch effects during inference—an affliction that plagues conventional models. The unerring influence of a single input on the routing and prediction for multiple inputs becomes a relic of the past, as Soft MoE elevates the efficiency and accuracy of predictions. What’s more, Soft MoE outshines its competitors in the race to optimize training timelines, outperforming ViT H/14 while requiring just half the training duration. It conquers the upstream domain, exhibits excellence in few-shot scenarios, and excels in finetuning. Even when compared to ViT H/14, Soft MoE B/16, boasting 5.5 times the parameters, emerges as the swifter contender, accelerating inference speeds by an impressive 5.7 times.
Conclusion:
Soft MoE’s revolutionary approach to sparse Transformers marks a turning point for the market. By tackling computational hurdles, dynamic routing, and efficiency barriers, Soft MoE presents an opportunity for industries to embrace unprecedented Transformer scalability. Its agile adaptation, elimination of batch effects, and impressive performance enhancements position it as a formidable tool, reshaping business strategies and technological paradigms alike.