
TL;DR:
- Stanford researchers introduce ‘Sophia,’ a novel second-order optimizer for language model pre-training.
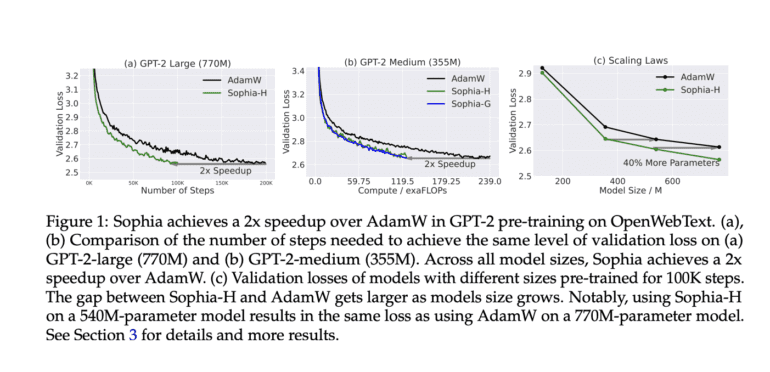
- Sophia achieves a remarkable speed boost, completing LLM training twice as fast as the traditional Adam optimizer.
- The optimizer utilizes a lightweight estimate of the diagonal Hessian as a pre-conditioner for accelerated performance.
- Sophia’s element-by-element clip after each update mitigates non-convexity effects and rapid Hessian changes.
- Implementation of Sophia with PyTorch is straightforward, reducing the need for gradient clipping and enhancing pre-workout steadiness.
- Sophia ensures consistent loss reduction across all parameter dimensions, outperforming Adam even in two-dimensional space.
- This advancement empowers academics to explore LLM pre-training with greater ease and develop innovative algorithms.
- Researchers plan to introduce a modified version of the widely accepted definition of LR to further enhance performance.
Main AI News:
In the ever-evolving world of artificial intelligence, language models have emerged as an indispensable tool, but their training comes with a hefty price tag. However, a glimmer of hope has appeared on the horizon. Stanford researchers have introduced a groundbreaking innovation in the optimization process that promises to dramatically reduce the time and financial resources required for language model training. Meet ‘Sophia’ – a scalable second-order optimizer that is set to reshape the future of language model pre-training.
For a considerable period, the go-to optimization technique had been Adam and its variants, while second-order (Hessian-based) optimizers were largely overlooked due to their high per-step overhead. Sophia is about to change that narrative by making a resounding impact on the efficiency of language model training.
The core of Sophia’s power lies in its lightweight estimate of the diagonal Hessian, serving as the pre-conditioner for the second-order optimization process. This novel approach, named Second-order Clipped Stochastic Optimization, is a game-changer. It has the remarkable capability of accelerating the training of large language models by a staggering factor of two compared to the traditional Adam optimizer.
The magic happens with an ingenious element-by-element clip after each update. This clip is computed by taking the mean of gradients and dividing it by the mean of the estimated Hessian. The result is a controlled update size that mitigates the impact of the trajectory’s non-convexity and rapid Hessian changes, thus avoiding worst-case scenarios.
As an enticing bonus, implementing Sophia with PyTorch is a breeze. It requires only a lightweight estimate of the diagonal Hessian as a pre-condition on the gradient, and the rest falls neatly into place. Additionally, the need for frequent gradient clipping, which can be cumbersome with other optimizers like Adam and Lion, is drastically reduced. Sophia achieves a remarkable steadiness, thanks to its clever re-parameterization trick that eliminates the requirement for focused temperature variation with the layer index.
Moreover, Sophia’s brilliance lies in its ability to ensure consistent loss reduction across all parameter dimensions. By penalizing updates more heavily in sharp sizes (those with a large Hessian) and being gentler with flat dimensions (those with a small Hessian), Sophia outperforms Adam even in two-dimensional space.
The implications of this undertaking are profound. Academics and researchers now have the confidence that, even with limited resources, they can delve into LLM pre-training and devise novel and effective algorithms. The research process itself is enriched by a fusion of theoretical reasoning and insights gleaned from previous optimization courses.
The impact of Sophia extends even further. In the upcoming release, researchers plan to unveil a slightly modified version of the widely accepted definition of LR (learning rate) for language model training. This revision aims to strike a perfect balance between clarity in the paper and precision in computer code.
Conclusion:
The introduction of ‘Sophia’ represents a significant breakthrough in the language model pre-training market. With its scalable second-order optimization approach, Sophia offers unparalleled speed and efficiency, potentially revolutionizing the industry. Academics and researchers can now harness the power of this novel optimizer to explore LLM pre-training with limited resources, leading to the development of cutting-edge algorithms. As ‘Sophia’ paves the way for faster and more cost-effective language model training, it holds the potential to reshape the landscape of artificial intelligence and fuel transformative advancements in various industries. Businesses should keep a close eye on this disruptive technology to stay ahead in the evolving market.