
TL;DR:
- SPHINX is a Multi-Modal Large Language Model (MLLM) that overcomes limitations in processing visual instructions and executing diverse tasks.
- It adopts a unique threefold mixing strategy, integrating model weights, tuning tasks, and visual embeddings.
- The model excels in processing high-resolution images and collaborates with other visual foundation models, enhancing its capabilities.
- SPHINX demonstrates superior performance in tasks like referring expression comprehension, human pose estimation, and object detection.
- Its adaptability and versatility in enhancing object detection positions it as a frontrunner in multi-modal language models.
- The introduction of SPHINX opens doors to future exploration and innovation in the field of vision-language understanding.
Main AI News:
In the realm of multi-modal language models, a profound challenge has come to the forefront – the inherent limitations of existing models when dealing with intricate visual instructions and seamlessly executing a wide array of diverse tasks. The crux of the matter lies in the pursuit of models that transcend conventional boundaries, possessing the capability to grasp complex visual queries and perform a spectrum of tasks, ranging from understanding referring expressions to tackling intricate feats like human pose estimation and nuanced object detection.
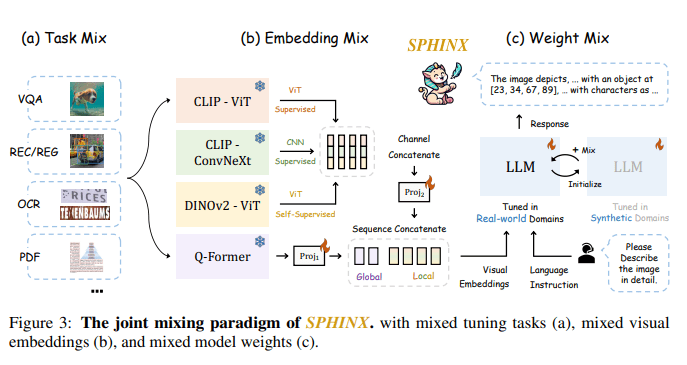
Enter SPHINX, an innovative solution conceived by a dedicated research team to address these existing limitations. This Multi-Modal Large Language Model (MLLM) takes a giant leap forward by adopting a unique threefold mixing strategy. Departing from traditional approaches, SPHINX seamlessly integrates model weights from pre-trained large language models, engages in diverse tuning tasks using a judicious blend of real-world and synthetic data, and fuses visual embeddings from disparate vision backbones. This amalgamation positions SPHINX as an unparalleled model, poised to excel across a broad spectrum of vision-language tasks that have proven to be challenging.
Diving into the intricate workings of SPHINX’s methodology unveils a sophisticated integration of model weights, tuning tasks, and visual embeddings. A standout feature is the model’s prowess in processing high-resolution images, ushering in an era of fine-grained visual comprehension. SPHINX’s collaboration with other visual foundation models, such as SAM for language-referred segmentation and Stable Diffusion for image editing, amplifies its capabilities, showcasing a holistic approach to addressing the complexities of vision-language understanding. A comprehensive performance evaluation solidifies SPHINX’s superiority across various tasks, from referring expression comprehension to human pose estimation and object detection. Notably, SPHINX’s ability to enhance object detection through hints and anomaly detection underscores its versatility and adaptability, positioning it as a frontrunner in the dynamic realm of multi-modal language models.
In conclusion, the researchers triumphantly address the existing limitations of vision-language models with the groundbreaking introduction of SPHINX. The threefold mixing strategy ushers in a new era, propelling SPHINX beyond established benchmarks and highlighting its competitive edge in visual grounding. The model’s capacity to transcend traditional tasks and showcase emerging cross-task abilities foreshadows a future brimming with unexplored possibilities and applications.
The discoveries presented in this article not only offer a solution to contemporary challenges but also open the door to a horizon of future exploration and innovation. As the research team propels the field forward with SPHINX, the broader scientific community eagerly anticipates the transformative impact of this innovative approach. SPHINX’s success in tackling tasks beyond the initial problem statement positions it as a pioneering contribution to the ever-evolving field of vision-language understanding, promising unprecedented advancements in multi-modal language models.
Conclusion:
SPHINX’s groundbreaking approach and superior performance in multi-modal language tasks present significant opportunities in the market, particularly in areas requiring advanced visual understanding and natural language processing. Its adaptability and potential for future innovations make it a valuable asset for businesses seeking to harness the power of AI in diverse applications.