
TL;DR:
- Stability AI unveils Japanese Vision-Language Model, Japanese InstructBLIP Alpha.
- This model marks the first to generate Japanese text descriptions.
- It excels at recognizing Japanese landmarks, offering localized awareness.
- The model handles text and images for complex visual queries.
- Training involves a combination of an image encoder, LLM, and Q-Former.
- Exceptional performance across 13 diverse datasets.
- Introduction of “instruction-aware visual feature extraction.”
- Caution about potential biases and the need for human judgment.
Main AI News:
In the ever-evolving realm of artificial intelligence research, the pursuit of an all-encompassing model capable of seamlessly handling diverse user-defined tasks has been a focal point. This quest, often referred to as “instruction tuning,” has significantly impacted the field of Natural Language Processing (NLP). Through this method, the efficacy of a large language model (LLM) is enhanced by exposing it to a wide array of activities, each conveyed through natural language instructions.
A prime example of this innovation is the Vision-Language Model, or VLM. These AI systems possess the remarkable ability to comprehend both textual and visual inputs, facilitating a wide spectrum of tasks that involve the interplay of visual and textual data. Their applications span from image captioning and visual question answering to generating textual descriptions of visual scenes and language translation alongside visual representations.
The latest breakthrough in this domain comes from the research team at Stability AI, who have recently introduced their pioneering Japanese vision-language model, known as Japanese InstructBLIP Alpha. In a landscape crowded with vision-language models, this release distinguishes itself as the first to generate Japanese text descriptions. The core objective of this innovative algorithm is to furnish Japanese text descriptions for incoming images while also providing textual responses to image-related queries.
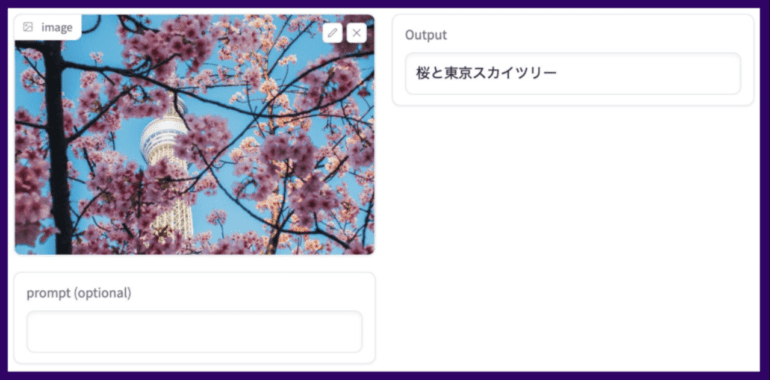
One of the standout features of this model is its capability to identify specific Japanese landmarks, a functionality that holds immense potential across a multitude of domains, from robotics to the tourism industry. Furthermore, its proficiency in handling both text and images allows for more intricate queries based on visual inputs.
The development of this model was underpinned by rigorous research, drawing upon a diverse array of instruction data. To achieve this, the researchers combined an image encoder, a large language model (LLM), and a Query Transformer (Q-Former). Notably, the Q-Former was fine-tuned for instruction tuning, while the image encoder and LLM remained frozen.
The researchers meticulously curated 26 publicly available datasets encompassing a wide spectrum of functions and responsibilities, transforming them into an instruction tuning format. The model was then trained on 13 of these datasets, showcasing state-of-the-art zero-shot performance across all 13 held-out datasets. Additionally, when fine-tuned for individual downstream tasks, the model continued to exhibit exceptional performance. To enhance instruction awareness, the researchers designed a Query Transformer capable of extracting information elements specific to the given instruction.
A groundbreaking concept introduced in this research is “instruction-aware visual feature extraction,” a methodology that enables the extraction of adaptable and informative features in alignment with provided instructions. To enable the Q-Former to retrieve instruction-aware visual features from the frozen image encoder, textual instructions are concurrently fed into both the frozen LLM and the Q-Former. This approach is complemented by a balanced sampling technique that synchronizes the learning progress across datasets.
However, the researchers caution users to remain vigilant about potential biases and limitations, underscoring that, like any AI system, the model’s responses should be assessed for accuracy and appropriateness using human judgment. They acknowledge that there is room for improvement in the model’s performance in Japanese vision-language tasks and commit to ongoing research and development efforts in pursuit of further refinement.
Conclusion:
Stability AI’s groundbreaking Japanese Vision-Language Model, Japanese InstructBLIP Alpha, heralds a significant advancement in the field of artificial intelligence. With its ability to generate Japanese text descriptions, identify landmarks, and handle complex visual queries, it holds the potential to transform industries such as robotics and tourism. This innovation underscores the growing importance of instruction tuning and instruction-aware feature extraction in AI development, signaling new opportunities and challenges for the market. However, it is imperative for users to exercise caution and human judgment to ensure the accuracy and appropriateness of the model’s responses.