
TL;DR:
- Convolutional neural networks (CNNs) are essential for sequence modeling but face speed challenges due to hardware limitations.
- Stanford’s FlashFFTConv optimizes the Fast Fourier Transform (FFT) convolution for extended sequences.
- It introduces a Monarch decomposition to strike a balance between FLOP and I/O costs.
- FlashFFTConv boosts model quality and efficiency, outperforming PyTorch and FlashAttention-v2.
- It enables handling longer sequences and opens new possibilities in AI applications.
Main AI News:
Efficiency in processing long sequences has long been a challenge in the field of machine learning. Convolutional neural networks (CNNs) have recently gained prominence as a critical tool for sequence modeling, offering top-notch performance across various domains, from natural language processing to computer vision and genetics. Despite their remarkable qualities, convolutional sequence models have lagged behind Transformers in terms of speed. This limitation can be attributed in part to inadequate hardware support.
The Fast Fourier Transform (FFT) convolution algorithm, which calculates convolutions between input sequences and kernels by manipulating frequency domains, holds the potential to overcome this challenge. However, the practical implementation of the FFT convolution has faced hurdles in terms of execution time, especially on contemporary accelerators.
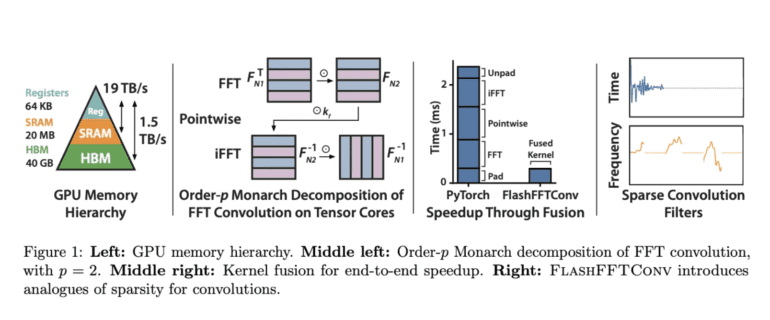
Researchers at Stanford University have taken up the mantle to address this bottleneck head-on. They are striving to optimize the FFT convolution method for modern accelerators, believing that this endeavor will not only improve convolutional sequence models but also unlock new algorithmic possibilities.
Optimizing the FFT convolution for shorter sequences has been a common practice, involving the reuse of kernel filters across multiple batches and precomputation of FFTs. This approach allows for parallelization across batches and filters, while kernel fusion enables intermediate convolution outputs to be efficiently cached.
However, as sequence length grows, two major obstacles emerge. First, FFT convolutions fail to fully leverage specialized matrix-matrix multiply units in contemporary accelerators. Second, kernel fusion becomes impractical as sequences exceed the capacity of SRAM, necessitating costly I/O operations. Padding for causality and transformations from real to complex-valued FFT intermediates further exacerbate these I/O costs.
In response, Stanford’s researchers introduce FlashFFTConv, a groundbreaking algorithm that harnesses a Monarch decomposition of the FFT to optimize convolutions for extended sequences. This decomposition reimagines the FFT as a series of matrix-matrix multiply operations, with the choice of decomposition order, denoted as “p,” impacting FLOP and I/O costs. A trade-off between these factors comes into play.
The study provides insights into optimizing “p” for FLOP and I/O costs in a GPU using a straightforward cost model based on sequence length. This decomposition not only facilitates kernel fusion for longer sequences but also reduces the amount of sequence data that must reside in SRAM. FlashFFTConv can effectively handle sequences ranging from 256 to a staggering 4 million characters. Leveraging a real-valued FFT algorithm and optimizing matrix-multiply operations for zero-padded inputs, FlashFFTConv can reduce FFT operation length by up to 50%.
Moreover, FlashFFTConv offers a versatile framework for implementing two architectural modifications: partial convolutions and frequency sparse convolutions. These techniques are akin to sparse and approximate attention mechanisms in Transformers, significantly lowering memory usage and runtime.
The results are nothing short of remarkable. FlashFFTConv accelerates FFT convolutions, enhancing the quality and efficiency of convolutional sequence models. For the same computational budget, it enables improvements such as a 2.3-point reduction in perplexity for Hyena-GPT-s and up to a 3.3-point increase in average GLUE score for M2-BERT-base. This performance boost is akin to doubling the model’s parameter size.
FlashFFTConv also excels in efficiency, offering up to 7.93 times better efficiency and up to 5.60 times more memory savings compared to PyTorch. Importantly, these efficiency gains persist across a wide range of sequence lengths, making FlashFFTConv a formidable contender. It even outpaces FlashAttention-v2 in wall-clock time for sequences of 2K or longer, thanks to reduced FLOP costs, achieving up to 62.3% end-to-end FLOP usage.
But the story doesn’t end there. FlashFFTConv enables models to handle longer sequences, breaking barriers previously thought insurmountable. It has conquered the Path-512 job, a high-resolution picture classification task with a sequence length of 256K, and extended HyenaDNA to a remarkable 4 million sequence length using partial convolutions.
Conclusion:
Stanford’s FlashFFTConv presents a game-changing advancement in optimizing FFT convolutions for long sequences. This breakthrough technology promises to reshape the landscape of convolutional sequence models, enhancing their quality and efficiency. It opens doors to handling longer sequences and offers potential applications in various domains, signaling a significant market shift towards more efficient machine learning solutions.