
- Machine learning models face vulnerabilities due to retained data, prompting the need for unlearning strategies.
- Traditional methods lack efficacy against deep neural networks’ interpolation capabilities.
- A novel approach champions instance-wise unlearning, ensuring robust information leakage prevention.
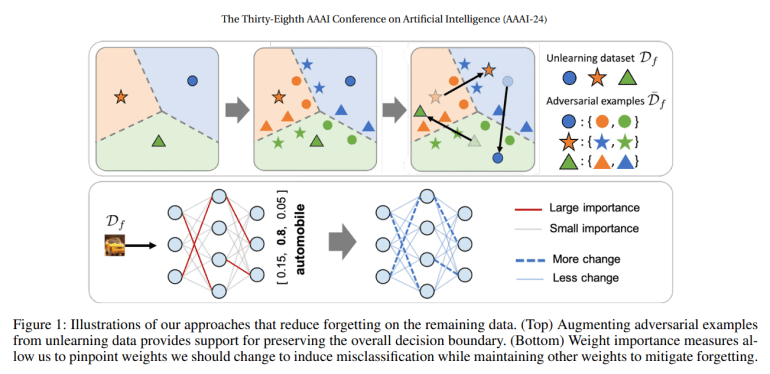
- The framework combines adversarial examples and weight importance metrics for resilient model adaptation.
- Experimental validation across diverse datasets affirms superior performance in preserving accuracy and preempting misclassification.
Main AI News:
In today’s tech landscape, the ubiquity of machine learning models in pivotal domains underscores the imperative of safeguarding against potential vulnerabilities. Once entrenched in a dataset, these models harbor data indefinitely, rendering them susceptible to breaches, adversarial exploits, and bias entrenchment. Hence, there’s a pressing need for methodologies facilitating model unlearning, enabling the erasure of specific subsets to mitigate privacy risks and fortify resilience against exploitation.
Initially, unlearning techniques primarily targeted shallow models such as linear regression and random forests, adept at excising undesirable data sans performance compromise. Recent strides have extended this purview to encompass deep neural networks, delineating two key modalities: class-wise, which expunges entire cohorts while upholding performance integrity, and instance-wise, honing in on individual data points. Yet, extant methodologies, oriented towards retraining sans extraneous data, falter against deep networks’ interpolation prowess, predisposing data leakage vulnerabilities.
A recent breakthrough, spearheaded by a collaborative effort from LG, NYU, Seoul National University, and the University of Illinois Chicago, introduces a paradigm shift in mitigating prevailing methodological constraints. Departing from class-wise assumptions and data accessibility dependencies, this novel approach champions instance-wise unlearning, anchored in a stringent information leakage prevention mandate. Notably, the framework mandates the misclassification of all slated data for deletion, ensuring robust efficacy.
The framework’s operational schema entails a meticulously orchestrated interplay between dataset delineation, pre-trained model configuration, and a dual-pronged unlearning regimen. Adversarial examples, instrumental in retaining class-specific insights and delineating decision contours, synergize with weight importance metrics, fortifying parameter prioritization to forestall inadvertent memory attrition. This cohesive strategy not only bolsters performance benchmarks but also circumvents access constraints, offering an agile yet potent recourse.
Experimental validation, conducted across CIFAR-10, CIFAR-100, ImageNet-1K, and UTKFace benchmarks, unequivocally underscores the newfound method’s efficacy. Leveraging adversarial examples (ADV) in tandem with weight importance metrics (ADV+IMP) for regularization purposes, the approach excels in sustaining accuracy fidelity across diverse testing scenarios. Even amidst continual unlearning exigencies and rectifying natural adversarial anomalies, the method eclipses conventional benchmarks, affirming its resilience and efficacy in preserving decisional fidelity and preempting misclassification proclivities. These empirical findings resonate as a clarion testament to the paradigmatic shift ushered in by this novel unlearning modality, heralding a more secure and robust AI landscape.
Conclusion:
This novel approach to unlearning dynamics signifies a pivotal advancement in fortifying AI systems against vulnerabilities. By prioritizing instance-wise unlearning and integrating adversarial examples with weight importance metrics, it not only enhances performance but also circumvents access constraints, ensuring a more agile and potent recourse for securing AI applications. This evolution in AI fairness has far-reaching implications, bolstering trust and confidence in AI systems across diverse market sectors.