
- Stumpy addresses the challenges of high computational costs and sensitivity to noise in time series analysis.
- It uses matrix profiles to record distances between subsequences and their nearest neighbors.
- Key techniques include optimized algorithms, parallel processing, and early termination.
- Optimized algorithms reduce redundant computations and improve efficiency.
- Parallel processing accelerates the handling of large datasets.
- Early termination conserves resources by halting computations when certain conditions are met.
- Stumpy’s performance was validated using Numba JIT-compiled code on various datasets and hardware setups.
- It significantly outperforms traditional methods in terms of speed and scalability.
Main AI News:
Time series data, essential across diverse sectors such as finance, healthcare, and sensor networks, demands robust methods for detecting patterns and anomalies. Traditional time series analysis approaches often struggle with high computational costs and sensitivity to noise, resulting in limited efficiency for large-scale and real-time applications. Stumpy emerges as a groundbreaking tool designed to address these challenges with enhanced performance and scalability.
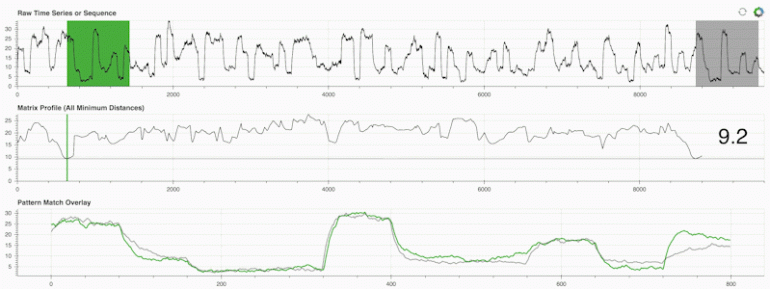
Stumpy introduces a novel approach to time series analysis by utilizing matrix profiles. The matrix profile is a vector that measures the distances between every subsequence within a time series and its nearest neighbor, enabling effective identification of recurring patterns (motifs), outliers (anomalies), and discriminative subsequences (shapelets). This method represents a significant advancement over traditional techniques, which are often constrained by their computational complexity and inability to handle large datasets efficiently.
The innovative capabilities of Stumpy are underpinned by several key techniques:
- Optimized Algorithms: Stumpy utilizes specialized algorithms tailored for rapid matrix profile computation. These algorithms minimize redundant calculations and improve accuracy while significantly reducing computational demands.
- Parallel Processing: To address the challenge of large datasets, Stumpy harnesses parallel computing capabilities. This approach accelerates data processing and analysis, making it feasible to handle extensive datasets much more efficiently than conventional methods.
- Early Termination: Stumpy incorporates early termination techniques that allow computations to be halted before completion when certain predefined conditions are met. This strategy conserves computational resources and reduces the overall time required for analysis.
The effectiveness of Stumpy has been rigorously tested through its implementation with the Numba JIT-compiled version of its code. Evaluations involved a range of time series data with varying lengths and utilized different CPU and GPU hardware resources. The results demonstrated Stumpy’s superior performance in terms of speed and scalability compared to previous methods. This advancement enables data scientists and analysts to derive valuable insights from time series data with greater efficiency, supporting a variety of applications from anomaly detection to pattern discovery and classification.
Conclusion:
Stumpy’s introduction marks a pivotal advancement in time series analysis, offering a scalable and efficient solution that overcomes the limitations of traditional methods. Its advanced matrix profiling techniques and performance enhancements position it as a valuable tool for data scientists and analysts. This development is likely to drive greater efficiency in handling large-scale datasets and real-time applications, potentially setting new standards in the market for time series analysis tools and methodologies.