
TL;DR:
- Tencent AI Lab introduces Progressive Conditional Diffusion Models (PCDMs) for pose-guided person image synthesis.
- PCDMs consist of three key stages: Prior Conditional Diffusion Model, Inpainting Conditional Diffusion Model, and Refining Conditional Diffusion Model.
- PCDMs address challenges in posing inconsistencies and producing high-quality, realistic images.
- Validation through experiments on public datasets demonstrates competitive performance.
- PCDMs show promise for applications in e-commerce content generation and person re-identification.
Main AI News:
The realm of pose-guided person image synthesis has witnessed remarkable advancements in recent times, with a particular focus on the creation of images depicting individuals in different poses while maintaining their original appearance. This technological innovation holds tremendous potential for e-commerce content generation and promises to enhance various downstream applications, such as person re-identification. However, the journey has not been without its share of challenges, most notably the inconsistencies that arise when transitioning between source and target poses.
Researchers have diligently explored various methodologies, including GAN-based, VAE-based, and flow-based techniques, to address the complexities inherent to pose-guided person image synthesis. While GAN-based approaches demand stable training but may yield unrealistic outcomes, VAE-based methods can inadvertently blur details and misalign poses. Flow-based models, on the other hand, have the potential to introduce undesirable artifacts. Some approaches employ parsing maps but grapple with style and texture issues. Diffusion models, though promising, confront their own set of challenges tied to pose inconsistencies, which necessitate careful consideration for improved results.
In response to these challenges, a recent paper has introduced a groundbreaking solution in the form of Progressive Conditional Diffusion Models (PCDMs). This novel approach systematically generates high-quality images through a three-stage process, encompassing the prediction of global features, the establishment of dense correspondences, and the refinement of images to achieve superior texture and detail consistency.
The PCDMs framework represents a significant leap forward in the domain of pose-guided person image synthesis. It introduces a straightforward yet effective prior conditional diffusion model that produces global features for the target image by aligning the source image’s appearance with the target pose coordinates. An innovative inpainting conditional diffusion model subsequently establishes dense correspondences, converting the previously unaligned image-to-image generation task into a meticulously aligned process. Furthermore, a refining conditional diffusion model elevates image quality and fidelity to new heights.
The PCDMs framework is divided into three key stages, each contributing substantially to the overall image synthesis process:
- Prior Conditional Diffusion Model: In the initial stage, the model predicts the global features of the target image by leveraging the alignment relationship between pose coordinates and image appearance. This is achieved through a transformer network conditioned on the source and target image poses, as well as the source image itself. The global image embedding, obtained from the CLIP image encoder, guides the synthesis of the target image. The loss function in this stage encourages the direct prediction of the un-noised image embedding, effectively bridging the gap between the source and target images at the feature level.
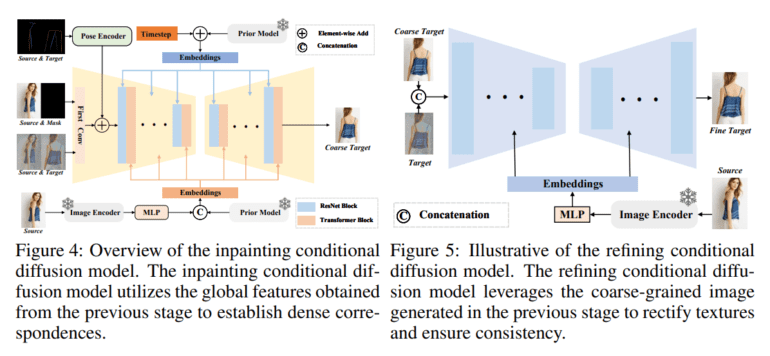
- Inpainting Conditional Diffusion Model: The second stage introduces the inpainting conditional diffusion model, which builds upon the global features obtained in the prior stage. It plays a pivotal role in establishing dense correspondences between the source and target images, transforming the unaligned image-to-image generation task into a precisely aligned endeavor. This stage ensures alignment across multiple dimensions, including image, pose, and feature, and is crucial for achieving realistic results.
- Refining Conditional Diffusion Model: Following the generation of an initial coarse-grained target image in the preceding stage, the refining conditional diffusion model steps in to enhance image quality and texture detail. This stage leverages the coarse-grained image generated earlier as a condition, further elevating image fidelity and ensuring texture consistency. It involves modifications to the first convolutional layer and employs an image encoder to extract features from the source image. The cross-attention mechanism is employed to infuse texture features into the network, facilitating texture repair and detail enhancement.
The effectiveness of this method has been rigorously validated through comprehensive experiments conducted on public datasets. These experiments have demonstrated competitive performance, as indicated by quantitative metrics such as SSIM, LPIPS, and FID. Moreover, a user study has provided further validation of the method’s effectiveness. An ablation study has meticulously examined the impact of each stage of the PCDMs framework, underscoring their individual significance. Lastly, the applicability of PCDMs in the domain of person re-identification has been showcased, revealing marked improvements in re-identification performance compared to baseline methods.
Conclusion:
Tencent AI Lab’s Progressive Conditional Diffusion Models (PCDMs) represent a significant breakthrough in the field of pose-guided person image synthesis. With the ability to generate high-quality images and address challenges related to pose inconsistencies, PCDMs have the potential to revolutionize the market for e-commerce content generation and person re-identification solutions. Businesses and industries that rely on image synthesis and recognition technologies should closely monitor the developments in PCDMs, as they offer a promising avenue for enhancing the quality and realism of generated images, ultimately improving user experiences and outcomes.