

TL;DR:
- El Capitan supercomputer at Lawrence Livermore National Laboratory is poised to become the most powerful system in the world.
- HPC centers globally are unlikely to field a machine that can surpass El Capitan’s capabilities.
- AI startups are funding big AI supercomputers, but at a higher cost compared to El Capitan.
- Inflection AI’s machine, costing $1.35 billion, would rank second on the Top500 list.
- El Capitan’s estimated peak performance exceeds that of Inflection AI’s machine at a lower cost.
- Microsoft is building a GPU cluster for OpenAI, costing $1.21 billion, with lower performance compared to El Capitan.
- US national labs benefit from lower costs per unit of computing compared to commercial sector players.
- El Capitan’s remarkable achievements exemplify the benefits of Moore’s Law and advanced engineering.
- The market is witnessing intense competition between supercomputers and AI upstarts, with continuous advancements pushing technological boundaries.
Main AI News:
In the race for computing supremacy, the “El Capitan” supercomputer has made its grand entrance at the Lawrence Livermore National Laboratory. This powerful system has already captured the attention of the scientific community with its impressive capabilities. However, the real question now is not whether El Capitan will reign as the world’s most potent supercomputer, but for how long it can maintain its dominance.
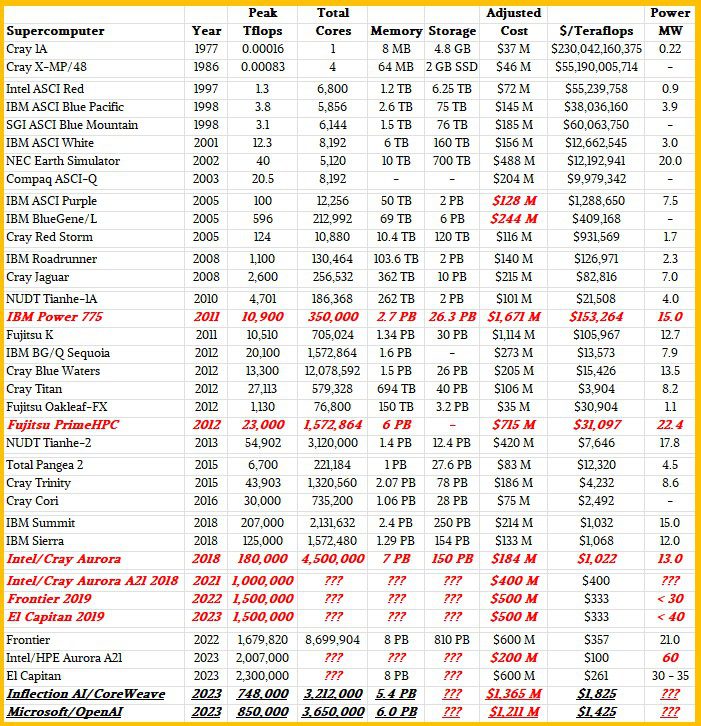
El Capitan has the potential to hold its ground for a significant period. When it comes to the AI-driven supercomputers that AI startups are backing, an old adage comes to mind: “You can find better, but you can’t pay more.” None of the major high-performance computing (HPC) centers around the globe seems capable of fielding a machine that can surpass El Capitan’s might. It’s a persistent powerhouse that outshines its competitors, with an estimated peak FP64 performance of 2.3 exaflops. That’s a remarkable 37 percent more power than the previous record-holder, the “Frontier” supercomputer at Oak Ridge National Laboratory.
Looking back to 2018, when the CORAL-2 contracts were awarded, expectations were already high. Frontier was anticipated to deliver 1.3 exaflops FP64 peak performance for $500 million using custom AMD CPUs and GPUs. El Capitan, on the other hand, was projected to achieve the same peak performance for the same cost, utilizing off-the-shelf AMD processors. During this time, the revised “Aurora A21” was also slated to reach around one exaflop for an estimated $400 million. Unfortunately, all three machines faced installation delays, stretching the anticipation since 2015 when HPC labs began planning for exascale computing. In the end, AMD secured the contracts for Frontier and El Capitan, surpassing bids from IBM and Nvidia, who had previously built the “Summit” and “Sierra” systems at Oak Ridge and Lawrence Livermore. Although these are mere conjectures, one thing is clear: the hyperscalers, cloud builders, and AI startups are forces to be reckoned with.
These industry players are venturing into the realm of massive machines that could potentially surpass traditional HPC systems in lower precision AI training work. Nvidia and CoreWeave are collaborating on a project for Inflection AI, while Microsoft Azure is developing its own AI-focused systems. These machines, along with their venture capital funding, hold the promise of exceeding the capabilities of the current giants. However, let’s not discount the fact that they come at a steep price. These new systems, though powerful, are considerably more expensive than the exascale HPC systems in the United States.
Source: The Next Platform
Now, let’s dive into some comparative math as we unveil the early glimpses of El Capitan from Lawrence Livermore.
To start our analysis, let’s focus on the unnamed system being built for Inflection AI, which we discussed last week when El Capitan’s images surfaced. This Inflection AI machine appears to utilize 22,000 Nvidia H100 SXM5 GPU accelerators. Based on our limited knowledge of H100 and InfiniBand Quantum 2 networking pricing, we estimate its cost to be around $1.35 billion. Configured with nodes similar to a DGX H100 node featuring 2 TB of memory, 3.45 TB of flash, and eight 400 Gb/sec ConnectX-7 network interfaces, this system would offer a peak FP64 performance of 748 petaflops. This places it second on the current Top500 list, behind Frontier’s 1.68 exaflops FP64 peak and ahead of the “Fugaku” system at RIKEN Lab in Japan with its 537.2 petaflops FP64 peak.
It is essential to consider the pricing dynamics in this context. Demand for GPU compute engines from both Nvidia and AMD is incredibly high, making deep discounts unlikely. As a result, these machines come with a hefty price tag, making them considerably more expensive than their exascale HPC counterparts. While the Inflection AI machine’s FP16 half precision performance reaches an impressive 21.8 exaflops, its cost and capabilities are surpassed by El Capitan.
Speaking of El Capitan, we don’t yet know the FP16 matrix math performance of its AMD Instinct MI300A CPU-GPU hybrid, codenamed “Antares.” However, with the available information and our informed speculation, we believe El Capitan will outperform Inflection AI’s machine. Our estimates suggest that El Capitan could house around 23,500 MI300 GPUs, delivering a remarkable 18.4 exaflops of FP16 matrix math peak performance. This accounts for approximately 80 percent of the AI training power found in Inflection AI’s system, all at a lower cost and with greater FP64 performance.
Now, let’s turn our attention to the rumored 25,000 GPU cluster that Microsoft is constructing for OpenAI to train GPT-5. Historically, Azure has relied on PCI-Express versions of Nvidia accelerators, combined with InfiniBand networking, to build its HPC and AI clusters. It is reasonable to assume that this rumored cluster will feature Nvidia H100 PCI-Express cards, amounting to a significant investment of $500 million. Adding a pair of Intel “Sapphire Rapids” Xeon SP host processors, 2 TB of memory, and ample local storage brings the total cost to an estimated $1.21 billion for 3,125 nodes housing 25,000 GPUs. Factoring in InfiniBand networking costs based on Nvidia’s 20 percent rule would add another $242 million to the total. Although some may argue for discounts on server nodes, the cost per node remains substantial at $387,455, considering the high demand for AI systems.
With these considerations in mind, the Microsoft/OpenAI cluster is projected to reach 19.2 exaflops of FP16 matrix math peak performance, assuming sparsity is turned off. The PCI-Express versions of the H100 GPUs have fewer streaming multiprocessors than their SXM5 counterparts, resulting in approximately 11.4 percent lower performance at a lower cost.
These price differentials emphasize the significant gap between the US national labs and the commercial sector. HPC centers worldwide pursue novel architectures, positioning themselves as pioneers in research and development. This strategy enables them to commercialize their achievements in the long run. However, hyperscalers and cloud builders possess similar capabilities and are equally adept at performing the same calculations. Moreover, they have the advantage of developing their own compute engines, as demonstrated by Amazon Web Services, Google, Baidu, and Facebook to varying degrees. Despite potential discounts, the Inflection AI and OpenAI machines still exceed the cost per unit of compute when compared to the US national labs. El Capitan, for instance, will occupy a footprint similar to that of the retired “ASCI Purple” and “Sequoia” supercomputers built by IBM for Lawrence Livermore. El Capitan’s power and cooling requirements, estimated between 30 and 35 megawatts at peak, necessitated a doubling of data center capacity to accommodate this and the next exascale-class machine expected in 2029, running side by side.
For comparison, the ASCI Purple machine installed at Lawrence Livermore in 2005, also built by IBM, delivered a peak performance of 100 teraflops at FP64 precision while consuming approximately 5 megawatts of power. It was estimated to cost $128 million. In contrast, El Capitan’s performance potential is a staggering 23,000 times greater, with power draw ranging from 6 to 7 times higher and a cost 3.9 times greater. Although it may fall short of the exponential growth once envisioned for supercomputing centers, El Capitan’s achievements are still extraordinary. This success story owes its credit to Moore’s Law and the clever engineering behind the packaging, networking, power, and cooling.
We eagerly await the real numbers for El Capitan and the Aurora A21 system at Argonne National Laboratory. If our suspicions are correct, and Intel indeed wrote off $300 million of the $500 million Argonne contract, it is unlikely that a cheaper AI and HPC solution exists elsewhere in the world. Although Argonne pays in time and electricity usage, what truly matters now is the successful construction and utilization of these machines for actual HPC and AI workloads.

El Capitan is in a raised floor datacenter environment, and you have to reinforce the floor to wheel those “Shasta” Cray XE racks from Hewlett Packard Enterprise into place. Source: The Next Platform
Conclusion:
The emergence of the “El Capitan” supercomputer and the competition it faces from AI upstarts signifies a dynamic market for high-performance computing. El Capitan’s dominance is expected to remain unchallenged for some time, thanks to its exceptional performance and lower costs compared to commercial sector machines. However, AI startups are investing heavily in powerful supercomputers, albeit at a higher price point. This trend reflects the increasing demand for AI training capabilities and highlights the competitive landscape within the industry. As technology continues to advance, the market will witness further breakthroughs, shaping the future of supercomputing and AI-driven computing.