
TL;DR:
- InternLM-20B introduces a 20 billion parameter pretrained model.
- It employs a profound 60-layer architecture for superior performance.
- Meticulous data preparation enhances language understanding and reasoning.
- The model outperforms existing models in various language-related tasks.
- It supports an impressive 16k context length, offering versatility in NLP applications.
Main AI News:
In the ever-evolving realm of natural language processing, researchers are in constant pursuit of models that can emulate human-like text understanding, reasoning, and generation. The challenges lie in decoding intricate linguistic subtleties, bridging language divides, and adapting to a multitude of tasks. Conventional language models, constrained by limited depth and training data, have often fallen short of these ambitious goals. Enter InternLM-20B, a groundbreaking 20 billion parameter pretrained model designed to surmount these challenges.
InternLM-20B represents a significant departure from its predecessors in both architecture and data quality. While earlier models typically favored shallower architectures, InternLM-20B embraces a profound 60-layer structure. The rationale behind this choice is simple yet profound: as model parameters multiply, deeper architectures wield the power to elevate overall performance.
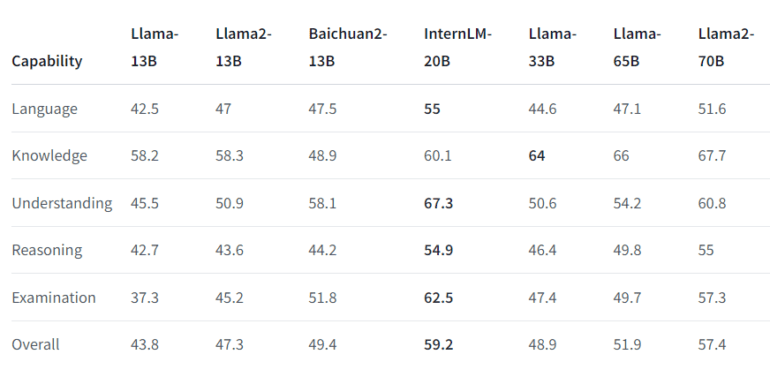
What truly distinguishes InternLM-20B is its meticulous approach to training data. The research team embarked on a rigorous data cleansing journey, augmented by the infusion of knowledge-rich datasets during pretraining. This painstaking preparation has significantly bolstered the model’s capabilities, enabling it to excel in language comprehension, reasoning, and knowledge retention. The outcome is nothing short of extraordinary—an exceptional model that consistently delivers outstanding performance across a spectrum of language-related tasks, heralding a new era in natural language processing.
InternLM-20B’s methodology hinges on the effective utilization of copious amounts of high-quality data during the pretraining phase. With its towering 60-layer architecture, this model accommodates an unprecedented number of parameters, thereby enabling it to capture intricate textual patterns with unparalleled finesse. This depth empowers the model to shine in the realm of language understanding, a cornerstone of NLP.
What truly sets InternLM-20B apart is the caliber of its training data. The research team meticulously curated a vast and exceptionally high-quality dataset, leaving no stone unturned in the pursuit of excellence. This comprehensive approach, including rigorous data cleansing and the integration of knowledge-rich datasets, has bestowed upon the model the ability to excel across a multitude of dimensions.
InternLM-20B’s prowess is clearly reflected in various evaluation benchmarks, where it consistently outperforms existing models in language comprehension, reasoning, and knowledge retention. Its support for an impressive 16k context length stands as a substantial advantage, particularly in tasks demanding an extensive textual context. As such, InternLM-20B emerges as a versatile tool, finding application in diverse NLP domains, ranging from chatbots to language translation and document summarization.
Conclusion:
The introduction of InternLM-20B represents a significant leap forward in the field of natural language processing. Its deep architecture, meticulous data preparation, and exceptional performance across language-related tasks position it as a game-changer. This innovation opens doors to more advanced NLP applications, offering exciting opportunities for businesses to leverage their capabilities in various market segments, including chatbots, language translation, and document summarization.