
TL;DR:
- Vector databases are crucial for Language Models (LLMs) in the AI revolution.
- Vector embedding enhances data representation and long-term memory retention.
- Traditional databases struggle with the complexity of vector embedding.
- Vector databases offer optimized storage, search capabilities, and data retrieval for vector embeddings.
- Implementing vector databases is challenging but essential for high-performance outcomes.
- Vector databases enable efficient query processing through indexing, querying, and post-processing stages.
- They revolutionize AI systems by providing accurate similarity searches and faster outputs.
- Vector databases are transforming the market, empowering companies to engage effectively with users and deliver superior experiences.
Main AI News:
In today’s fast-paced world, where chatbots, LLMs, and GPT dominate conversations, it’s crucial to delve into the realm of vector databases and understand their significance for Language Models (LLMs). As new LLMs emerge at an astonishing pace, it becomes imperative to recognize the pivotal role vector embedding plays in these cutting-edge applications. Let us explore what vector databases are and why they hold paramount importance for LLMs.
Understanding Vector Databases: Unleashing the Potential of Vector Embedding
Before we dive deeper, let’s grasp the concept of vector embedding. Vector embedding refers to a data representation technique that encapsulates semantic information, enabling AI systems to comprehend data comprehensively while retaining long-term memory. When acquiring new knowledge, understanding the subject matter and committing it to memory form the crux of the learning process. This is where embeddings generated by AI models, such as LLMs, come into play. These embeddings encompass a multitude of features, making their representation complex yet invaluable. By incorporating different dimensions of the data, embeddings empower AI models to discern relationships, identify patterns, and uncover hidden structures.
Challenges of Vector Embedding and the Rise of Vector Databases
However, employing traditional scalar-based databases to handle vector embedding poses a significant challenge. The scale and complexity of the data overwhelm these databases, rendering them inadequate for efficient management. Given the intricate nature of vector embedding, one can imagine the need for a specialized database to address its requirements. Enter vector databases—a groundbreaking solution to the conundrum.
Vector databases are purpose-built to optimize storage, facilitate seamless queries, and cater to the unique structure of vector embeddings. They empower users with streamlined search capabilities, unparalleled performance, scalability, and efficient data retrieval by comparing values and identifying similarities. At first glance, this solution seems remarkable, but let’s not overlook the inherent challenges that come with implementing vector databases.
The Path to Implementing Vector Databases: A Complex Journey
Implementing vector databases has long been the domain of tech giants blessed with both the expertise to develop them and the resources to manage them. With significant costs associated with vector databases, ensuring proper calibration becomes essential to achieve high-performance outcomes. Until now, vector databases remained elusive for most entities, confined to the realm of the privileged few.
Decoding the Mechanics of Vector Databases: Powering LLMs’ Efficiency
Having familiarized ourselves with the fundamentals of vector embedding and databases, let’s delve into how vector databases function, using the example of a prominent LLM, ChatGPT. ChatGPT, renowned for its vast volumes of data and content, offers valuable insights into the operational workflow of vector databases. The following steps outline the process:
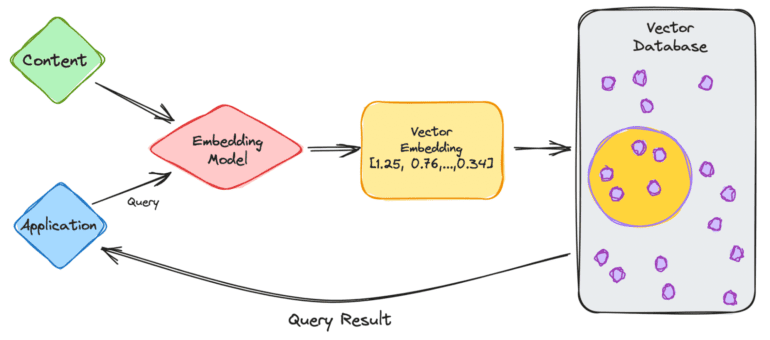
- User Input: You, as the user, provide your query through the application.
- Embedding Model: Your query enters the embedding model, which generates vector embeddings based on the desired content for indexing.
- Vector Database: The resulting vector embedding interacts with the vector database, associating it with the content from which the embedding originated.
- Query Result: The vector database produces an output, which is then transmitted back to you as a query result.
As you continue to make subsequent queries, the process repeats itself, employing the embedding model to create embeddings for querying the database for similar vector embeddings. The similarities between these vector embeddings stem from the original content that served as the foundation for their creation.
Delving Deeper into Vector Database Functionality: The Paradigm Shift
To comprehend the inner workings of vector databases, let’s compare them to traditional databases. Traditional databases typically store strings, numbers, and other data types in rows and columns. When querying these databases, we search for rows that match our specific query criteria. However, vector databases operate differently. Instead of dealing with strings or other data types, they handle vectors. Moreover, vector databases employ a similarity metric to identify vectors most akin to the query.
A vector database comprises various algorithms that facilitate the Approximate Nearest Neighbor (ANN) search. This encompasses techniques such as hashing, graph-based search, and quantization, which merge into a cohesive pipeline for retrieving neighbors of a queried vector. The final results are determined by the proximity or approximation of each vector to the query, emphasizing the significance of accuracy and speed. A slower query output tends to deliver more precise results.
Key Stages of a Vector Database Query: Indexing, Querying, and Post Processing
A typical vector database query undergoes three fundamental stages:
- Indexing: As mentioned earlier, once the vector embedding enters the vector database, an array of algorithms maps it to data structures, enabling faster search operations.
- Querying: Once the search process commences, the vector database compares the queried vector with indexed vectors, utilizing the similarity metric to identify the nearest neighbor.
- Post Processing: Depending on the chosen vector database, it undergoes post-processing to generate the final output for the query. This stage may involve re-ranking the nearest neighbors for future reference, ensuring optimal outcomes.
Embracing the Potential: Revolutionizing AI with Vector Databases
As the AI landscape continues to flourish, witnessing the release of new systems with staggering regularity, the exponential growth of vector databases assumes a pivotal role. Leveraging vector databases empowers companies to engage more effectively with their users, delivering accurate similarity searches and lightning-fast outputs. So, the next time you input a query into ChatGPT or Google Bard, take a moment to reflect upon the intricate process that unfolds behind the scenes to produce the results you seek.
Conclusion:
Vector databases play a critical role in the AI market, particularly for LLMs. They enhance the capabilities of these models by enabling efficient data representation and retrieval, leading to better user experiences. As vector databases become more accessible and cost-effective, we can expect an accelerated adoption of AI systems across various industries, driving innovation and opening new avenues for businesses to leverage the power of intelligent technologies.