
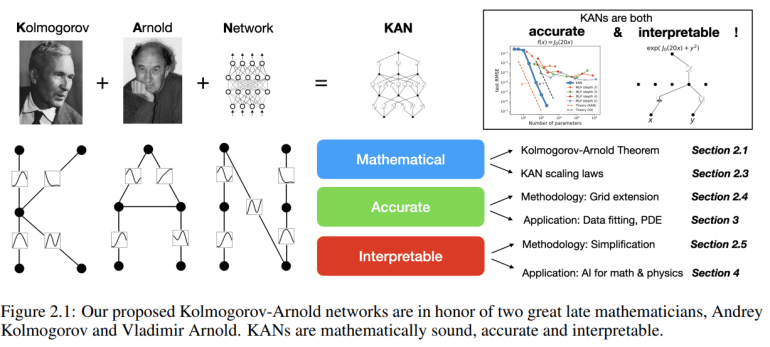
- Kolmogorov-Arnold Networks (KANs) are proposed as a superior alternative to Multi-layer Perceptrons (MLPs) in deep learning.
- KANs introduce learnable activation functions on edges, surpassing MLPs in accuracy and interpretability.
- They leverage the Kolmogorov-Arnold Representation Theorem, employing univariate B-spline curves for function representation.
- KANs outperform MLPs across various tasks, including regression, solving partial differential equations, and continual learning.
- They offer interpretability by revealing compositional structures and topological relationships, holding promise for scientific discovery.
- KANs present a compelling choice over MLPs when interpretability and accuracy are crucial, despite slower training.
Main AI News:
In the realm of deep learning, multi-layer perceptrons (MLPs), also known as fully-connected feedforward neural networks, have long been the cornerstone for approximating nonlinear functions. Despite their widespread use and the backing of the universal approximation theorem, MLPs come with their share of limitations. One notable drawback is their lack of interpretability, especially when compared to attention-based models like transformers. While researchers have explored alternatives such as the Kolmogorov-Arnold representation theorem, much of the focus has been on traditional MLP architectures, overlooking advancements in training methodologies like backpropagation. Consequently, there’s a persistent quest for more effective nonlinear regressors within neural network design.
Enter Kolmogorov-Arnold Networks (KANs), conceived as a viable alternative to MLPs by researchers from MIT, Caltech, Northeastern, and the NSF Institute for AI and Fundamental Interactions. Unlike MLPs, which rely on fixed node activation functions, KANs introduce learnable activation functions on edges, replacing linear weights with parametrized splines. This fundamental shift empowers KANs to outperform MLPs in both accuracy and interpretability. Backed by rigorous mathematical and empirical analyses, KANs demonstrate superior performance, especially in handling high-dimensional data and addressing scientific problem-solving challenges. This groundbreaking study not only introduces the KAN architecture but also conducts comparative experiments with MLPs, highlighting the interpretability and applicability of KANs in scientific discovery.
While previous research has explored the intersection of the Kolmogorov-Arnold theorem (KAT) and neural networks, much of it has been confined to limited network architectures and simplistic experiments. This study breaks new ground by expanding the scope of KANs to arbitrary sizes and depths, thus aligning it with contemporary deep learning requirements. Additionally, the research addresses Neural Scaling Laws (NSLs), showcasing how KANs enable rapid scaling while maintaining performance. Moreover, the study delves into Mechanistic Interpretability (MI) by designing inherently interpretable architectures, showcasing the potential of continuously learned activation functions in KANs. Furthermore, KANs show promise in domains like Physics-Informed Neural Networks (PINNs) and mathematical AI applications, particularly in knot theory.
Inspired by the Kolmogorov-Arnold Representation Theorem, which posits that any bounded multivariate continuous function can be expressed through single-variable continuous functions and addition operations, KANs leverage this concept by employing univariate B-spline curves with adjustable coefficients to represent functions across multiple layers. By stacking these layers, KANs deepen, aiming to overcome the limitations of the original theorem and achieve smoother activations for improved function approximation. Theoretical guarantees, such as the KAN Approximation Theorem, provide insights into the bounds of approximation accuracy. Compared to other theories like the Universal Approximation Theorem (UAT), KANs offer promising scaling laws owing to their low-dimensional function representation.
In empirical evaluations, KANs consistently outshine MLPs in representing functions across diverse tasks such as regression, solving partial differential equations, and continual learning. Their superiority in accuracy and efficiency is particularly evident in capturing the intricate structures of special functions and Feynman datasets. Additionally, KANs exhibit interpretability by revealing compositional structures and topological relationships, underscoring their potential for scientific breakthroughs in fields like knot theory. They also hold promise in addressing unsupervised learning challenges, providing insights into the underlying structural relationships among variables. Overall, KANs emerge as formidable and interpretable models for AI-driven scientific research.
Conclusion:
KANs represent a paradigm shift in deep learning, leveraging mathematical principles to enhance both interpretability and accuracy. While their training may be slower compared to MLPs, KANs excel in tasks where interpretability and accuracy are paramount. Although optimizing training speed remains an ongoing challenge, the potential benefits of KANs make them a compelling choice over MLPs, especially when interpretability and accuracy take precedence and time constraints are manageable. However, for tasks prioritizing speed, MLPs continue to be the more pragmatic option.