
TL;DR:
- Researchers from The University of Hong Kong, TikTok, Zhejiang Lab, and Zhejiang University have introduced ‘Depth Anything.’
- It’s a foundational model for Monocular Depth Estimation (MDE) with remarkable depth estimation capabilities from images.
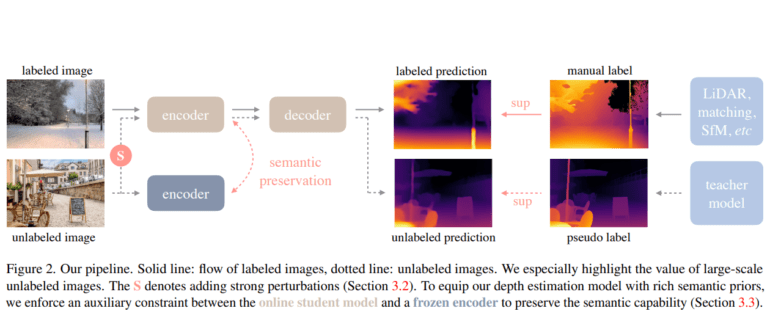
- Utilizes large-scale unlabeled data for cost-effective and diverse depth annotations.
- Combines labeled and unlabeled data for improved depth estimation through a self-learning pipeline.
- Emphasizes joint learning and leverages semantic priors from pre-trained encoders for enhanced scene understanding.
- Outperforms MiDaS v3.1 in zero-shot depth estimation across diverse datasets.
- Superior performance in semantic segmentation suggests potential for use in multi-task visual perception systems.
Main AI News:
Foundational models, the cornerstone of modern deep learning, serve as the bedrock upon which effective machine learning models are constructed. Leveraging extensive training data, these models exhibit exceptional zero and few-shot performance across a plethora of tasks, making them indispensable in the domains of natural language processing and computer vision. In particular, these foundational models play a pivotal role in Monocular Depth Estimation (MDE), the art of gauging depth from a single image, a critical component in the realms of autonomous vehicles, robotics, and virtual reality. However, the challenge of amassing extensive depth-labeled datasets has hindered the full exploration of MDE, resulting in subpar performance of associated MDE models under certain conditions.
To tackle this formidable challenge, a team of visionary researchers hailing from The University of Hong Kong, TikTok, Zhejiang Lab, and Zhejiang University have birthed a foundational model tailored for MDE, one capable of generating high-fidelity depth information from images. While conventional depth datasets are painstakingly crafted using depth sensors, stereo matching, or Structure from Motion (SfM), in a pioneering approach, these researchers have set their sights on large-scale unlabeled data, which is not only easily attainable but also cost-effective, diverse, and amenable to annotation.
Their pioneering work harnesses both labeled and unlabeled data to enhance depth estimation, with a primary emphasis on the latter category. The research team amassed a staggering 1.5 million labeled images from six public datasets and, for the unlabeled trove, devised a depth engine that autonomously generates depth annotations. The labeled images were initially employed to train an MDE model, which in turn, propagated annotations onto the unlabeled data, creating a self-improving, self-learning pipeline.
In the crucible of joint learning, the model is subjected to more stringent optimization criteria, further enriching its knowledge base. Furthermore, the researchers put forth a novel proposition, advocating the utilization of rich semantic priors derived from pre-trained encoders, a departure from the conventional auxiliary semantic segmentation task. This innovative approach enhances scene comprehension, elevating the model’s prowess.
In a comprehensive evaluation, the researchers pitted their model’s zero-shot depth estimation capabilities against the state-of-the-art MiDaS v3.1 across six previously unseen datasets. The results unequivocally establish the supremacy of Depth Anything, surpassing the MiDaS model by a significant margin across diverse scenarios and previously uncharted datasets. Notably, the model even outperforms ZoeDepth, a MiDaS-based solution, in metric depth estimation. In addition, Depth Anything exhibits superior performance in semantic segmentation, reaffirming its potential as a versatile multi-task encoder for mid-level and high-level visual perception systems.
Conclusion:
The introduction of ‘Depth Anything’ marks a significant breakthrough in the field of Monocular Depth Estimation. Its ability to harness large-scale unlabeled data and deliver superior performance across various tasks has the potential to reshape the market for autonomous systems, robotics, and virtual reality. This innovation may drive the adoption of more cost-effective and versatile depth estimation solutions, fostering advancements in these industries.