
TL;DR:
- TrailBlazer introduces a game-changing approach in video synthesis using bounding boxes.
- It leverages the pre-trained Stable Diffusion (SD) model to address efficiency challenges in Text-to-Video (T2V) synthesis.
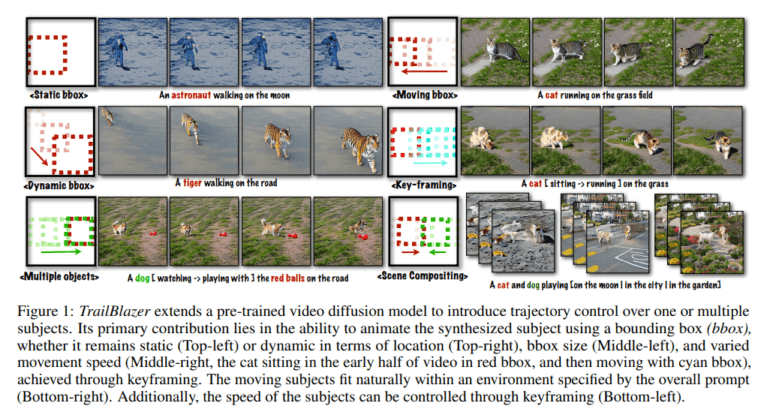
- Users can control object trajectories by providing bounding boxes and textual prompts.
- Spatial and temporal attention maps are manipulated during denoising diffusion for precise object placement.
- Users can keyframe bounding boxes and text prompts for dynamic video content creation.
- TrailBlazer is efficient, requiring no model finetuning, training, or online optimization.
- It delivers natural outcomes with perspective, precise object motion, and interactions.
- Limitations exist with deformed objects and generating multiple objects with precise attributes.
Main AI News:
The world of generative models has witnessed remarkable advancements in text-to-image (T2I) capabilities. More recently, the realm of text-to-video (T2V) systems has undergone a transformative evolution, enabling the seamless creation of videos based solely on textual prompt descriptions. However, one formidable challenge has loomed large in the field of video synthesis – the insatiable appetite for extensive memory and training data.
Enter the groundbreaking approach known as TrailBlazer, a brainchild of Victoria University of Wellington in collaboration with NVIDIA. TrailBlazer represents a pivotal shift in the landscape of Text-to-Video (T2V) synthesis by harnessing the power of the pre-trained Stable Diffusion (SD) model to tackle efficiency bottlenecks head-on.
The TrailBlazer methodology approaches the issue from multiple angles, incorporating techniques such as finetuning and zero-shot learning. Yet, the holy grail of video synthesis lies in achieving superior control over the spatial layout and object trajectories within the generated video content. Previous attempts have involved providing low-level control signals, such as Canny edge maps or tracked skeletons, to guide objects within the video. While effective, these methods demand significant effort in generating the control signals themselves.
Imagine the complexity of capturing the desired motion of an animal or a high-value object or the tedium of sketching each frame’s movement individually. Recognizing the need for simplicity and accessibility, the researchers at NVIDIA Research have introduced a high-level interface that empowers users to control object trajectories effortlessly in synthesized videos. How do they achieve this? By employing bounding boxes (bboxes) that specify the desired object positions at various points in the video, coupled with textual prompts describing the objects at corresponding times.
Their ingenious strategy involves the manipulation of spatial and temporal attention maps during the initial denoising diffusion steps. This focus allows for the concentration of activation precisely at the desired object locations, all without disrupting the learned text-image association within the pre-trained model. What’s more, this approach necessitates only minimal code modifications.
With this novel approach, users gain the ability to position subjects with precision through keyframing bounding boxes. The size of these bounding boxes can be adjusted to create compelling perspective effects. Furthermore, users can also influence the behavior of the subject by keyframing the text prompt, ushering in a new era of dynamic storytelling.
By animating bounding boxes and prompts through keyframes, users can seamlessly manipulate the trajectory and basic behavior of the subject over time. This empowers creators to seamlessly integrate their subjects into any desired environment, effectively transforming TrailBlazer into a user-friendly video storytelling tool.
Perhaps the most remarkable aspect of the TrailBlazer approach is its efficiency. It requires no model finetuning, training, or online optimization, ensuring a swift and smooth user experience. Additionally, it delivers natural outcomes by automatically incorporating desirable effects like perspective, precise object motion, and intricate interactions between objects and their surroundings.
However, it’s worth noting that TrailBlazer, like any other innovation, is not without its limitations. Challenges persist in dealing with deformed objects and the generation of multiple objects with precise attributes like color. Nonetheless, TrailBlazer stands as a pioneering leap forward in the realm of video synthesis, poised to revolutionize the way we create and interact with visual content.
Conclusion:
TrailBlazer’s innovative approach to video synthesis using bounding boxes opens new possibilities in content creation. Its efficiency and user-friendliness position it as a potential disruptor in the market, enabling both professionals and casual users to create engaging videos with ease. However, addressing limitations with deformed objects and attribute precision will be crucial for broader adoption and market dominance.