
- Deep learning revolutionizes genomics and imaging analysis by handling vast data.
- It automates feature extraction, enhancing predictive models without preconceived notions.
- In genomics, it predicts splicing, protein specificity, and mutation effects accurately.
- CNNs in imaging classify structures, cells, and tissues surpassing traditional methods.
- These advancements streamline workflows and improve computational efficiency.
Main AI News:
The convergence of advancements in genomics and imaging has ushered in an era of unprecedented data abundance, revolutionizing our understanding of molecular and cellular processes. Yet, traditional analytical methods struggle to grapple with the complexity and scale of these datasets. Enter deep learning, a branch of machine learning poised to unlock hidden insights and facilitate precise predictions by adeptly navigating vast troves of data. This article delves into the transformative applications of deep learning in regulatory genomics and cellular imaging, elucidating its efficacy, operational mechanisms, and potential hurdles.
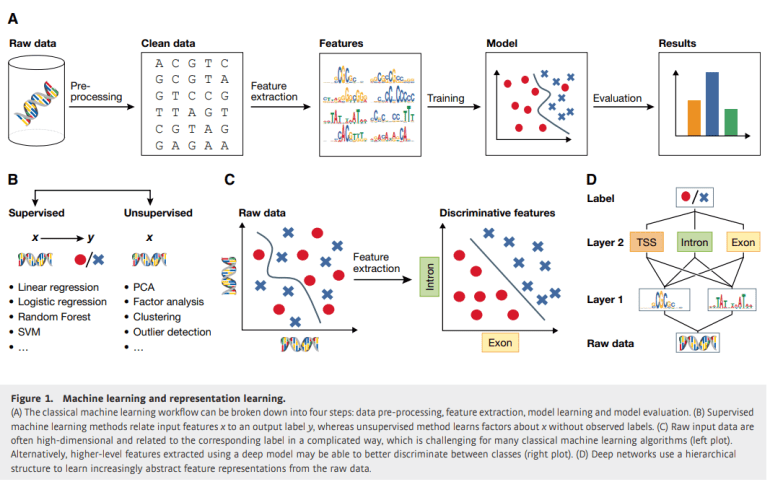
Deep learning, a subset of machine learning, streamlines the arduous task of feature extraction, thus enhancing the predictive capabilities of models without the need for predefined assumptions regarding underlying mechanisms. By traversing multiple layers of neural networks, deep learning encapsulates intricate functions by transmuting raw data into abstract feature representations. Its prowess in deciphering complex patterns has catalyzed significant advancements in image and computational biology.
Within the realm of computational biology, machine learning methodologies hold appeal for their ability to construct predictive models devoid of explicit knowledge about biological mechanisms. For instance, the prediction of gene expression levels from epigenetic cues or the assessment of cancer cell line viability following drug exposure entails the training of models like support vector machines or random forests. Despite occasional characterization as enigmatic “black boxes,” these models furnish invaluable predictions, even when the underlying biological interactions remain opaque. This review underscores the pivotal role of data preprocessing, feature extraction, model fitting, and evaluation in the machine learning workflow, accentuating the paradigm shift from manual to automated feature extraction facilitated by deep learning. Moreover, it furnishes pragmatic guidance for the application of these techniques in biology, elucidating contemporary software, potential stumbling blocks, and the comparative efficacy of deep learning vis-à-vis traditional methodologies.
Deep Learning Metamorphosis in Regulatory Genomics
Conventional approaches in regulatory genomics traditionally correlate sequence variations with molecular traits by pinpointing regulatory variants influencing gene expression, DNA methylation, histone modifications, and proteome fluctuations. However, these methods encounter constraints imposed by the variability within the training population, necessitating substantial sample sizes to investigate rare mutations. Deep neural networks surmount these limitations by autonomously discerning features from sequence data and encapsulating nonlinear dependencies and interactions across broader genomic contexts. They have proven instrumental in forecasting splicing activity, discerning DNA- and RNA-binding protein specificities, and deciphering epigenetic imprints, underscoring their utility in decoding DNA sequence perturbations.
Pioneering Applications and Evolution of Neural Networks in Regulatory Genomics
Initial forays of neural networks into regulatory genomics augmented conventional methodologies by harnessing deep models sans alterations to input features. For instance, a fully connected feedforward neural network prognosticated splicing activity leveraging pre-defined features, thereby attaining heightened precision and identifying rare mutations. Recent strides leverage convolutional neural networks (CNNs) to directly train on DNA sequences, obviating the prerequisite for pre-defined features. CNNs streamline model parameters by applying convolutional operations to localized input regions and parameter sharing, facilitating accurate predictions of DNA- and RNA-binding protein specificities, as well as functional single nucleotide variants.
Progress in Predicting Mutation Impacts and Concurrent Trait Projections Utilizing Deep Learning
Deploying deep neural networks to raw DNA sequences enables the in silico prediction of mutation effects, complementing quantitative trait locus (QTL) mapping and aiding in the identification of rare regulatory single nucleotide variants (SNVs). Mutation maps visually delineate these effects. Advancements in CNNs facilitate the simultaneous prediction of multiple traits, such as chromatin marks and DNase I hypersensitivity, from expansive DNA sequence windows. Multitask learning and CNN-based models like Basset have bolstered performance and computational efficiency. Additionally, recurrent neural networks (RNNs) and unsupervised learning models proffer alternative avenues for feature extraction and classification in regulatory genomics.
Deep Learning in Biological Image Analysis
Deep neural networks, particularly CNNs, have propelled biological image analysis to unprecedented heights. Initial endeavors centered on pixel-level classification, including the prognostication of cellular structures in C. elegans embryos and the detection of mitosis in breast histology images. These models outshine traditional methodologies such as Markov random fields. Innovations like U-Net have refined localization by amalgamating granular insights from early layers. Beyond pixel-level tasks, CNNs adeptly classify entire cells, tissues, and even bacterial colonies, eclipsing handcrafted feature approaches. The prevailing trend revolves around end-to-end analysis pipelines harnessing vast bioimage repositories and harnessing the formidable symbolic capabilities of CNNs.
Conclusion:
The integration of deep learning in genomics and imaging signifies a transformative shift in biological analysis. With its ability to handle vast datasets and automate complex tasks, deep learning not only enhances predictive accuracy but also streamlines workflows. This trend heralds a new era of efficiency and precision in biological research, promising significant market opportunities for innovative solutions and services catering to these domains.