
TL;DR:
- MAGNeT (Masked Audio Generation using Non-autoregressive Transformers) redefines audio generation.
- Operates with speed and precision across multiple streams of audio tokens.
- A non-autoregressive approach predicts masked tokens, speeding up audio creation.
- Introduces rescoring method for enhanced audio quality.
- The hybrid model combines autoregressive and non-autoregressive techniques.
- Demonstrates efficiency in text-to-music and text-to-audio generation.
- Seven times faster than traditional autoregressive models.
- The research analyzes the trade-offs and the significance of MAGNeT components.
Main AI News:
The world of audio technology has witnessed remarkable advancements in recent years, especially in the realm of audio generation. Yet, a significant challenge has persisted – the need for models that can swiftly and precisely create audio from diverse inputs, including textual descriptions. Traditional approaches, mainly relying on autoregressive and diffusion-based models, while impressive in their outcomes, have grappled with high inference times and struggled when tasked with generating extensive sequences.
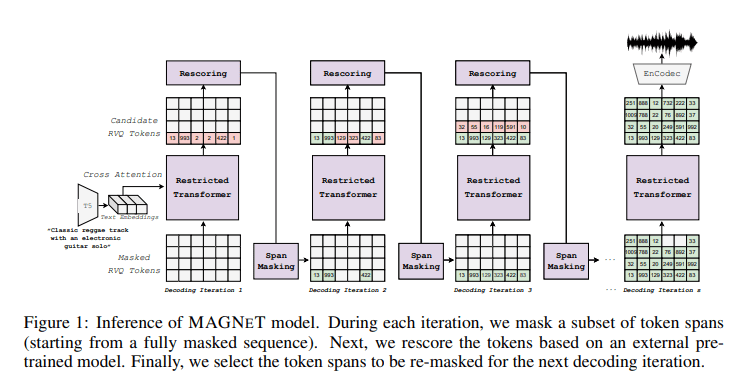
In response to these challenges, a triumphant collaboration between researchers from FAIR Team Meta, Kyutai, and The Hebrew University of Jerusalem has given birth to MAGNeT (Masked Audio Generation using Non-autoregressive Transformers). This groundbreaking methodology operates seamlessly across multiple streams of audio tokens, all within the confines of a single transformer model. Diverging from its predecessors, MAGNeT stands as a non-autoregressive innovation, predicting masked token spans through a masking scheduler during training. It gradually constructs the final audio output during inference, employing a series of decoding steps. This approach heralds a significant leap in efficiency, rendering it exceptionally suitable for interactive applications like music generation and editing.
One distinguishing facet of MAGNeT is its introduction of a unique rescoring mechanism, designed to elevate audio quality. This ingenious method harnesses an external pre-trained model to rescore and rank predictions originating from MAGNeT. These refined predictions then guide subsequent decoding steps. Furthermore, researchers have ventured into crafting a hybrid version of MAGNeT, fusing both autoregressive and non-autoregressive models. This hybrid variant handles the initial seconds of audio generation in an autoregressive fashion, while the remainder of the sequence is decoded in parallel.
The prowess of MAGNeT shines brightly in the domains of text-to-music and text-to-audio generation. Rigorous empirical evaluations, encompassing objective metrics and human studies, have showcased MAGNeT’s performance, putting it on par with existing baselines. What truly sets MAGNeT apart is its exceptional speed, particularly when compared to its autoregressive counterparts. Remarkably, MAGNeT operates at a staggering seven times the speed of traditional autoregressive models.
The research underlying MAGNeT delves deep into the nuances of each of its components, shedding light on the intricate balance between autoregressive and non-autoregressive modeling. The research team’s meticulous ablation studies and analysis illuminate the significance of various aspects of MAGNeT, providing invaluable insights into the world of audio generation technologies. MAGNeT stands as a beacon of innovation, driving the future of audio technology towards unprecedented efficiency and quality.
Conclusion:
MAGNeT’s introduction to the audio generation landscape signifies a transformative leap in speed and quality. Its non-autoregressive approach, unique rescoring method, and hybrid model have the potential to revolutionize interactive applications like music generation and editing. With a sevenfold increase in speed compared to autoregressive models, MAGNeT sets a new standard for efficiency in audio technology, promising significant market disruption and opportunities for innovation.