
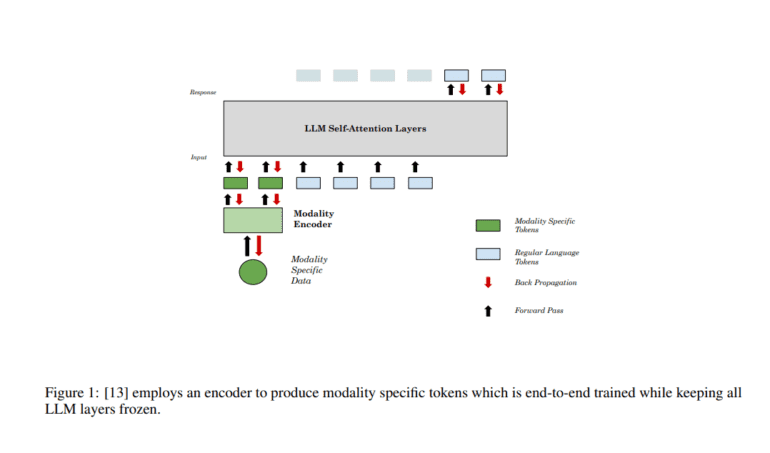
TL;DR:
- Researchers from Datategy SAS and the Math & AI Institute propose integrating Named Entity Recognition (NER) into multi-modal Large Language Models (LLMs).
- Multi-modal LLMs like LLaVA and Kosmos demonstrate their effectiveness in combining text and other data modalities.
- The authors envision an “omni-modal era” where various entities, including mathematical, temporal, and geospatial, become modalities.
- This approach addresses knowledge scaling, context length, and information injection challenges.
Main AI News:
In a groundbreaking collaboration between Datategy SAS in France and the Math & AI Institute in Turkey, researchers are charting a new course for the future of multi-modal architectures within the realm of Large Language Models (LLMs). Their innovative perspective revolves around integrating well-established Named Entity Recognition (NER) techniques into the vast landscape of multi-modal LLMs.
Recent strides in multi-modal architectures, exemplified by LLaVA, Kosmos, and AnyMAL, have showcased their prowess in the practical realm. These models transcend traditional text-based inputs, embracing data from diverse modalities such as images. Through the utilization of modality-specific encoders, these architectures seamlessly amalgamate various sources of information, offering a powerful mechanism for interleaving multi-modal data with textual content.
The authors of this study, however, envision a future that transcends current boundaries, one they aptly term the “omni-modal era.” Drawing parallels to the concept of NER, they propose that the very notion of “entities” could serve as modalities within these dynamic architectures.
For example, contemporary LLMs often grapple with intricate algebraic reasoning. While efforts are underway to craft specialized models or leverage external tools tailored for mathematical tasks, a promising avenue lies in defining quantitative values as a distinct modality within this framework. Similarly, the implicit and explicit identification of date and time entities can be efficiently processed through a temporally-cognitive modality encoder.
The challenges extend to geospatial comprehension, where current LLMs fall short of being “geospatially aware.” Here, the integration of locations as a dedicated geospatial modality, complete with a meticulously designed encoder and comprehensive joint training, holds the potential to bridge this gap. Furthermore, entities such as individuals, institutions, and more, can seamlessly become additional modalities within this multi-faceted architecture.
This innovative approach not only promises to address issues related to parametric/non-parametric knowledge scaling and context length limitations but also offers a pragmatic solution for injecting updated information through modalities. By distributing complexity and information across a myriad of modality encoders, this paradigm shift heralds a new era in entity-driven language models.
Conclusion:
The integration of Named Entity Recognition (NER) into multi-modal Large Language Models (LLMs) marks a significant advancement in the field. This “omni-modal era” concept promises to expand the capabilities of LLMs by treating various entities as modalities. For the market, this means the potential for more versatile and context-aware language models that can process diverse data sources effectively, paving the way for improved natural language understanding and a broader range of applications across industries.