
TL;DR:
- Google AI Research introduces TRICE, a novel machine learning algorithm for enhancing Large Language Models (LLMs) using Chain-of-Thought (CoT) Prompting.
- TRICE optimizes average log-likelihood for correct answers and maximizes marginal log-likelihood for accurate responses, significantly improving LLM performance.
- The study references related techniques like CoT, STaR, and more, highlighting their role in rationale generation within neural sequence models.
- TRICE instructs LLMs to generate answers step by step and introduces a Markov-chain Monte Carlo expectation-maximization algorithm.
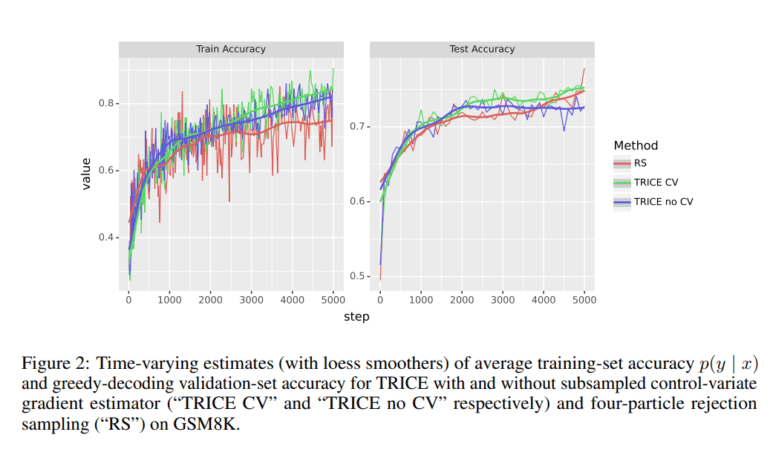
- Evaluation on GSM8K and BIG-Bench Hard tasks demonstrates TRICE’s superiority over other fine-tuning techniques.
- Control-variate technique is incorporated to reduce gradient estimate variance.
- TRICE offers potential for advancements in natural language processing and problem-solving.
Main AI News:
In a groundbreaking development, Google AI Research has unveiled TRICE, a cutting-edge machine learning algorithm designed to enhance the capabilities of Large Language Models (LLMs) in solving question-answering tasks. This innovative fine-tuning strategy, known as chain-of-thought (CoT) fine-tuning, focuses on optimizing the average log-likelihood of providing correct answers while maximizing the marginal log-likelihood of generating accurate responses. The result? A significant improvement in the overall performance of LLMs.
This pioneering study delves into the realm of rationale generation within neural sequence models, citing various related methodologies, such as fully supervised and few-shot approaches. Notably, the self-consistent CoT technique, renowned for its prowess in quantitative reasoning tasks, takes center stage for its ability to marginalize over rationales during testing. The study also explores STaR, which involves imputation or averaging over causes during training, among other relevant works, including Markovian score climbing, ReAct, Reflexion, and recent research on tool use within language models.
The research journey embarks on a quest to harness the potential of CoT prompting in elevating LLMs’ capabilities by instructing them to generate answers step by step. By fine-tuning LLMs using CoT prompts to maximize the marginal log-likelihood of producing accurate responses, the challenge of sampling from the posterior over rationales is effectively addressed. To accomplish this, a Markov-chain Monte Carlo expectation-maximization algorithm is introduced, inspired by a rich tapestry of related methods. The results are nothing short of impressive, showcasing the superior performance of this approach when compared to other fine-tuning techniques through rigorous evaluation on held-out examples.
Furthermore, this novel approach incorporates a control-variate technique to mitigate gradient estimate variance. The comprehensive evaluation spans across GSM8K and BIG-Bench Hard tasks, drawing comparisons with STaR, prompt-tuning with or without CoT, and task-specific templates, prompts, and memory initialization settings. Leveraging the power of TRICE and STaR techniques, along with adopting rejection sampling, CoT prompt tuning, and direct prompt tuning, the approach consistently outshines alternative methods, enhancing model accuracy across various challenging scenarios.
In summary, this research has unveiled an exceptional fine-tuning strategy that significantly enhances the accuracy of generating correct answers through CoT prompting. The consistent superiority of this technique, particularly in evaluating GSM8K and BIG-Bench Hard tasks, demonstrates its potential to revolutionize the field. CoT prompts have proven to be a powerful tool in training large language models for systematic problem-solving, resulting in improved accuracy and interpretability. The integration of the control-variate technique further adds to the model’s robustness, reducing gradient estimate variance.
Looking ahead, future research endeavors will explore the generalizability of the MCMC-EM fine-tuning technique across diverse tasks and datasets. Treating tool use as a latent variable, akin to rationales, holds promise for enhancing language models in tool-use scenarios. Comparative studies with alternative methods such as variational EM, reweighted wake-sleep, and rejection sampling will provide valuable insights. The synergy of the MCMC-EM technique with other approaches is expected to further elevate performance and interpretability. Additionally, investigating the applicability of the control-variate technique in reducing gradient estimate variance across various training scenarios and domains remains an intriguing avenue for exploration.
Conclusion:
The introduction of TRICE represents a significant leap in the capabilities of Large Language Models, with potential applications across various industries. This breakthrough in fine-tuning LLMs for question-answering tasks using CoT prompting opens doors for more accurate and interpretable natural language processing solutions. Businesses can leverage these advancements to enhance customer support, automate content generation, and improve data analysis, ultimately leading to increased efficiency and competitiveness in the market.