
- UC Berkeley researchers introduce LoRA+, an advancement in machine learning model fine-tuning.
- LoRA+ optimizes fine-tuning processes for large-scale models with extensive parameters.
- It addresses inefficiencies in existing methods by implementing distinct learning rates for adapter matrices.
- Rigorous testing showcases LoRA+’s superiority over traditional methods, with performance boosts and faster fine-tuning.
- The application of LoRA+ demonstrates remarkable test accuracies, particularly in complex tasks.
- The method signifies a strategic overhaul, enabling finer adaptation to specific task requirements.
Main AI News:
In the realm of deep learning, the pursuit of efficiency has triggered a paradigm shift in how we refine large-scale models. Led by Soufiane Hayou, Nikhil Ghosh, and Bin Yu from the University of California, Berkeley, a groundbreaking advancement has emerged in the form of LoRA+: an evolution of the Low-Rank Adaptation (LoRA) method. This innovation targets the optimization of model fine-tuning processes, especially for models characterized by their extensive parameter counts, often numbering in the tens or hundreds of billions.
Fine-tuning mammoth models for specific tasks has long been hindered by computational constraints. To circumvent this challenge, researchers have adopted strategies such as freezing the original weights of the model and adjusting only a fraction of the parameters through techniques like prompt tuning, adapters, and LoRA. The latter, in particular, involves training a low-rank matrix alongside the pre-trained weights, thereby reducing the parameters requiring adjustment.
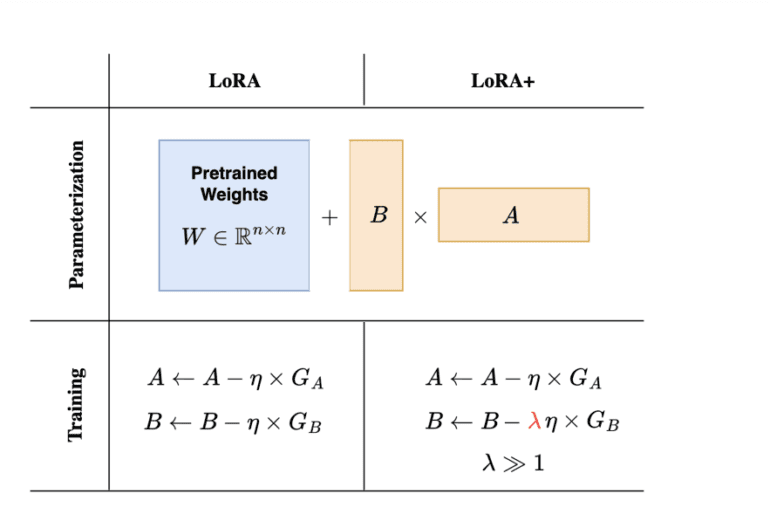
The UC Berkeley team identified a crucial inefficiency in the existing LoRA method: the uniform application of learning rates to the adapter matrices A and B. Given the expansive width of modern models, a one-size-fits-all approach to learning rates proves suboptimal, hampering feature learning. LoRA+ tackles this challenge head-on by introducing distinct learning rates for matrices A and B, optimized through a fixed ratio. This nuanced strategy ensures a tailored learning rate that aligns better with the scale and dynamics of large models.
Rigorous experimentation conducted by the team provides compelling evidence of LoRA+’s superiority over traditional LoRA. Across diverse benchmarks, including evaluations with Roberta-base and GPT-2 models, LoRA+ consistently outperformed its predecessor, showcasing enhancements in both performance and fine-tuning speed. Notably, performance improvements ranging from 1% to 2% and a doubling in fine-tuning speed were achieved, all while maintaining identical computational costs. These findings underscore LoRA+’s potential to revolutionize the fine-tuning landscape for large-scale models.
When applied to the Roberta-base model across varied tasks, LoRA+ demonstrated impressive test accuracies, particularly excelling in challenging tasks like MNLI and QQP compared to simpler ones like SST2 and QNLI. This performance variance highlights the significance of efficient feature learning, especially in intricate tasks where aligning the pre-trained model with the fine-tuning objective is less straightforward. Moreover, the successful adaptation of the Llama-7b model using LoRA+ on datasets like MNLI and Flan-v2 further validates the method’s effectiveness, showcasing substantial performance gains.
The methodology underpinning LoRA+, characterized by the implementation of distinct learning rates for LoRA adapter matrices with a fixed ratio, represents more than just a technical refinement; it signifies a strategic overhaul of the fine-tuning process. This approach enables a finer adaptation of models to specific task nuances, unlocking a level of customization previously unattainable through uniform learning rate adjustments.
Conclusion:
UC Berkeley’s introduction of LoRA+ marks a significant leap in machine learning fine-tuning, offering enhanced efficiency and performance for large-scale models. This breakthrough has the potential to reshape the landscape of machine learning by providing more effective tools for model adaptation, thereby opening up new possibilities for innovation and advancement in various industries reliant on AI technologies.