
TL;DR:
- UC Berkeley researchers propose an AI algorithm for goal-directed dialogues.
- Large Language Models (LLMs) excel in various natural language tasks but struggle in goal-directed conversations.
- The researchers introduce an innovative method that combines LLMs with reinforcement learning (RL) to enhance conversational outcomes.
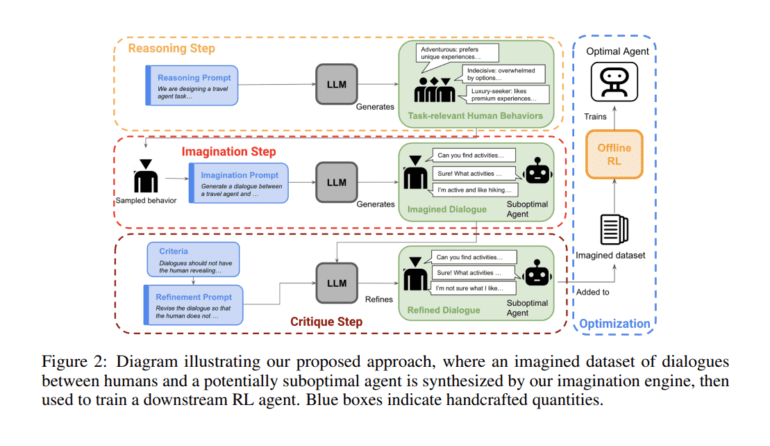
- Key contributions include an optimized zero-shot algorithm and an imagination engine (IE) for generating task-relevant questions.
- The IE collaborates with an LLM to produce effective agents for achieving desired outcomes.
- Multi-step reinforcement learning, using offline value-based RL, is employed to determine optimal strategies.
- Comparative evaluations demonstrate the superiority of the IE+RL approach over traditional LLMs.
- The practicality of their approach lies in utilizing a cost-effective model for data generation, reducing computational costs.
Main AI News:
Large Language Models (LLMs) have emerged as powerful tools in the realm of natural language processing, showcasing remarkable capabilities in tasks like text summarization, question answering, and code generation. However, when it comes to goal-directed conversations that require them to achieve specific objectives through dialogue, LLMs have often fallen short, providing verbose and impersonal responses.
Traditional methods, such as supervised fine-tuning and single-step reinforcement learning (RL), have struggled in this domain, as they lack optimization for overall conversational outcomes and fail to handle uncertainty effectively. In response to these challenges, researchers at UC Berkeley have introduced an innovative approach that combines LLMs with RL to enhance the performance of goal-directed dialogue agents.
Central to their contributions is an optimized zero-shot algorithm and a novel system known as the “imagination engine” (IE), designed to generate task-relevant and diverse questions for training downstream agents. The IE, while powerful in its own right, is further empowered through collaboration with an LLM, which generates potential scenarios.
To optimize the effectiveness of these agents in achieving desired outcomes, the researchers have employed multi-step reinforcement learning with a notable twist: instead of relying on on-policy samples, they leverage offline value-based RL learning policies from synthetic data.
To assess the efficacy of their methodology, the researchers conducted a comparative study between a GPT-based agent and the IE+RL approach, with human evaluators participating in goal-directed conversations based on real-world problems. Remarkably, the researchers utilized the GPT-3.5 model within the IE for synthetic data generation and a relatively modest decoder-only GPT-2 model as the downstream agent. This practical approach minimizes computational costs, making their methodology accessible and cost-effective.
Results from their experiments revealed that the proposed IE+RL agent consistently outperformed the GPT model across all metrics, ensuring the naturalness of resulting dialogues. Qualitatively, the IE+RL agent excelled in generating easy-to-answer questions and intelligently crafting follow-up queries based on previous interactions. A simulation-based evaluation also confirmed the superiority of the IE+RL agent over its GPT-based counterpart, solidifying the potential of this innovative approach for enhancing goal-directed dialogues.
Conclusion:
UC Berkeley’s innovative AI algorithm holds the potential to revolutionize the market for goal-directed dialogues. By enhancing conversational outcomes and reducing computational expenses, this breakthrough technology could open doors to more efficient and cost-effective solutions in various industries, such as customer support, virtual assistants, and automated consultations.