
TL;DR:
- UC San Diego and Meta AI unveil MonoNeRF, an autoencoder architecture that disentangles video into camera motion and depth maps without relying on ground-truth camera poses.
- MonoNeRF leverages temporal continuity in monocular videos to train on large-scale real-world datasets, enabling effective generalization and improved transferability.
- The model’s disentangled representations allow for monocular depth estimation, camera pose estimation, and single-image novel view synthesis without 3D camera pose annotations.
- MonoNeRF outperforms previous approaches in self-supervised depth estimation, camera pose estimation, and novel view synthesis on various datasets.
- For the business market, MonoNeRF offers enhanced video analysis capabilities, cost-effective scalability, and greater adaptability to real-world scenarios.
Main AI News:
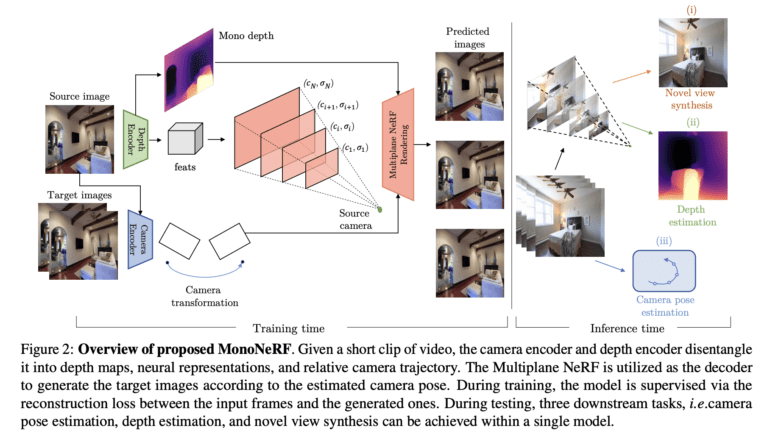
Cutting-edge research from UC San Diego and Meta AI has given rise to MonoNeRF, a groundbreaking autoencoder architecture that revolutionizes video analysis and synthesis in the world of business. This ingenious approach disentangles videos, extracting camera motion and depth maps through a sophisticated interplay of the Camera Encoder and the Depth Encoder, all without relying on ground-truth camera poses.
Neural Radiance Fields (NeRF) have shown remarkable promise across various fields, boasting applications in view synthesis, scene and object reconstruction, semantic understanding, and even robotics. However, the conventional construction of NeRF hinges on the availability of precise camera pose annotations, limiting its use to a single scene and resulting in painstakingly slow training procedures. The need for scalability in the face of unconstrained, large-scale video datasets has spurred recent research endeavors to tackle this challenge.
Efforts have been made to achieve generalizable NeRF models by training on diverse datasets comprising multiple scenes, followed by fine-tuning for individual scenarios. While this has led to successful reconstructions and view synthesis with fewer input views, it still necessitates camera pose information during training, restricting the full potential of the models. The pursuit of scene-specific NeRF training without camera poses has proven complex and has not yielded the desired cross-scene generalization, stalling progress in this realm.
Enter MonoNeRF, a game-changer in the field. The innovation lies in its approach to training on monocular videos capturing camera movements in static scenes, obviating the need for ground-truth camera poses altogether. This forward-thinking methodology is founded on the observation that real-world videos predominantly showcase gradual camera changes rather than diverse viewpoints. Leveraging this temporal continuity, the researchers have crafted a powerful Autoencoder-based model trained on a large-scale real-world video dataset.
The magic behind MonoNeRF lies in its depth encoder, estimating monocular depth for each frame, and its camera pose encoder, skillfully determining relative camera poses between consecutive frames. By creating disentangled representations, the researchers can construct a NeRF representation for each input frame, enabling the rendering and decoding of another input frame based on the estimated camera pose.
The researchers have implemented a reconstruction loss to ensure consistency between the rendered and input frames during training. To mitigate potential issues with misalignment between the estimated monocular depth, camera pose, and NeRF representation, they propose an innovative scale calibration method, guaranteeing harmony among the three representations.
The benefits of this cutting-edge framework are manifold. First and foremost, it liberates developers from the shackles of 3D camera pose annotations, streamlining the development process and reducing manual labor. Furthermore, MonoNeRF exhibits superior generalization on large-scale video datasets, fostering improved transferability and adaptability to real-world business applications.
At the heart of this innovation lies its applicability to a wide array of downstream tasks. From monocular depth estimation from a single RGB image to camera pose estimation and single-image novel view synthesis, the possibilities are vast. The researchers’ experiments, focused primarily on indoor scenes, attest to the effectiveness of their approach. MonoNeRF impressively outperforms its predecessors in self-supervised depth estimation on the Scannet test set and exhibits unmatched performance on NYU Depth V2. Additionally, in camera pose estimation, MonoNeRF consistently surpasses previous approaches, leaving the competition in the dust.
For novel view synthesis, the MonoNeRF approach is unmatched. Not only does it outperform methods that rely on ground-truth cameras, but it even surpasses recent approaches that learn without camera ground truth.
Conclusion:
MonoNeRF’s breakthrough in disentangling video data and generating Neural Radiance Fields without ground-truth camera poses is a game-changer for the business market. Its potential applications in video analysis and synthesis hold the promise of cost-effective scalability and increased adaptability, opening up new opportunities for businesses to leverage large-scale video datasets in various industries. This innovation puts businesses at the forefront of cutting-edge video technology, enabling them to make data-driven decisions with superior accuracy and efficiency.