
TL;DR:
- UniAudio introduces a universal audio generation system revolutionizing the field of audio production.
- It leverages Large Language Models (LLMs) for tasks such as text-to-speech, music production, and more.
- The system tokenizes audio formats and input modalities, using a universal neural codec model.
- A multi-scale Transformer architecture is employed to handle complex token sequences efficiently.
- UniAudio’s adaptability and scalability make it a foundational model for universal audio generation.
- It excels in 11 audio-generating tasks, outperforming task-specific models.
- UniAudio signifies the potential of universal audio generation models in the market.
Main AI News:
Generative AI has witnessed a meteoric rise in recent years, with audio generation standing at the forefront of its evolution. The demands for audio production have diversified, encompassing text-to-sound, text-to-music, speech synthesis (TTS), voice conversion (VC), singing voice synthesis (SVS), and much more. However, conventional approaches have been task-specific, reliant on domain expertise, and inflexible in their configurations. Enter UniAudio, a groundbreaking innovation poised to transform the landscape of audio generation.
UniAudio: A New Frontier in Audio Generation
The vision behind UniAudio is clear—to create a universal audio generation system capable of addressing a multitude of audio-generation tasks seamlessly. In this quest, UniAudio leverages the power of Large Language Models (LLM), a technology renowned for its prowess in text generation. While LLMs have excelled in text-to-speech (TTS) and music production, their potential to handle a diverse range of audio tasks remains underexplored.
Unlocking the Potential of LLM
Researchers from The Chinese University of Hong Kong, Carnegie Mellon University, Microsoft Research Asia, and Zhejiang University have collaborated to introduce UniAudio. This groundbreaking system harnesses LLM approaches to generate various audio genres, including speech, noises, music, and singing, using a range of input modalities such as phoneme sequences, textual descriptions, and audio itself.
Key Features of UniAudio
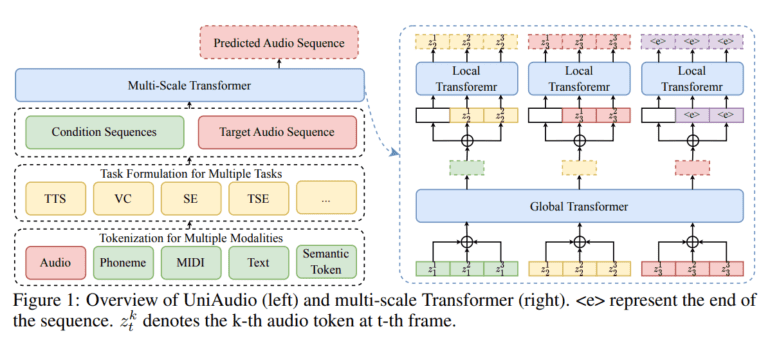
UniAudio employs a tokenization process that transforms all audio formats and input modalities into discrete sequences. To tackle the unique challenges posed by audio tokenization, a universal neural codec model is introduced, along with multiple tokenizers to handle diverse input types.
UniAudio takes the source-target pair and combines them into a unified sequence, paving the way for LLM-based next-token prediction. This tokenization technique, however, generates lengthy token sequences that traditional LLMs struggle to parse efficiently. To address this, UniAudio incorporates a multi-scale Transformer architecture that independently models inter- and intra-frame correlations. A global Transformer module captures correlations between frames, while a local Transformer module delves into correlations within frames.
Scalability and Adaptability
UniAudio’s strength lies in its scalability and adaptability. It undergoes two key steps: simultaneous training on various audio-generation tasks to acquire deep knowledge of audio qualities and relationships and fine-tuning to accommodate emerging audio creation activities seamlessly. This adaptability positions UniAudio as a foundational model for universal audio generation.
Impressive Performance
UniAudio stands as a testament to the potential of a universal audio generation. It excels in 11 audio-generating tasks, covering both training and fine-tuning stages, boasting 165k hours of audio data and 1B parameters. UniAudio consistently achieves competitive performance, surpassing task-specific models and swiftly adapting to new audio-generation challenges.
Conclusion:
UniAudio’s journey exemplifies the importance, promise, and advantages of universal audio generation models. It represents a significant step forward in the realm of generative AI, offering a solution that meets the evolving demands of audio production across various domains. With UniAudio, the future of audio generation is not only hopeful but transformative.