
TL;DR:
- IBM AI Research introduces Unitxt, a groundbreaking platform for unified textual data processing.
- Unitxt offers Python modules for handling textual data in multiple languages with customizable recipes.
- The platform includes a catalog of pre-defined recipes and built-in operators for enhanced efficiency.
- Collaboration, transparency, and reproducibility are emphasized through shared operators and recipes.
- Unitxt integrates seamlessly with HuggingFace datasets and existing code, eliminating the need for additional installations.
- It facilitates comprehensive evaluation frameworks, allowing adjustments across various dimensions.
- Unitxt serves as a vital data backbone for modern LLM training, simplifying dataset integration and model-specific formatting.
- It empowers academics and teams at IBM for various natural language processing tasks.
- Unitxt envisions a future of collaboration and progress in LLM development with the support of the open-source community.
Main AI News:
In the realm of natural language processing, the role of textual data processing has evolved into something truly transformative. This transformation is particularly evident in the function of Large Language Models (LLMs) as versatile interfaces, capable of understanding and executing a wide range of tasks and instructions expressed in natural language. The diversity of inputs, or prompts, that an LLM can receive has expanded significantly, encompassing task instructions, in-context examples, system prompts, and more. With this evolution comes the need for innovative methods and paradigms to assess and evaluate text generation models, given that the model outputs themselves represent rich textual data. Analyzing textual data for LLMs has become a complex endeavor, marked by numerous design decisions and characteristics that challenge the flexibility and reproducibility of LLM research.
Introducing Unitxt: A Groundbreaking Textual Data Processing Platform
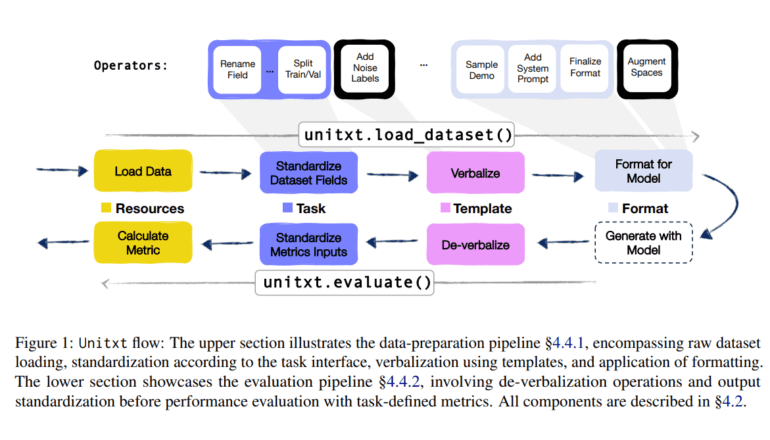
IBM Research proudly introduces Unitxt, a cutting-edge collaborative platform designed to streamline the processing of unified textual data. With the inclusion of a new Python module, Unitxt empowers users to work with textual data in multiple languages using customizable recipes, which are essentially configurable pipelines. These recipes encompass operators responsible for loading data, preprocessing, preparing various aspects of prompts, and evaluating model predictions. A rich catalog of pre-defined recipes for diverse tasks is at users’ disposal, promoting efficiency through reuse. Moreover, the catalog boasts a wide array of built-in operators forming the foundation for these recipes. This unified location fosters collaboration, transparency, and reproducibility by enabling the addition and sharing of operators and recipes among users. Unitxt’s modular framework allows users to mix and match ingredients to create new recipes, providing a level of flexibility akin to crafting a culinary masterpiece. This flexibility enables users to experiment with a vast array of recipe configurations, exceeding 100,000 possibilities. Unitxt also understands the hassle of transitioning between libraries and has been designed to seamlessly integrate with existing code, eliminating the need for pip installations.
Seamless Integration with HuggingFace Datasets
Unitxt further simplifies the data handling process by offering compatibility with HuggingFace datasets, ensuring that its outputs align seamlessly with other sections of your software. This feature facilitates a smooth transition and compatibility with existing workflows.
Elevating LLM Capabilities through Evaluation Frameworks
As the capabilities of LLMs continue to expand, the need for comprehensive evaluation frameworks becomes imperative. These frameworks must accommodate a vast array of datasets, workloads, and settings. Unitxt provides a solid foundation for such efforts, allowing for effortless adjustments across crucial dimensions such as languages, tasks, prompt structures, augmentation robustness, and more. The Unitxt Catalog plays a pivotal role in promoting collaboration among separate projects by facilitating the sharing of entire evaluation pipelines. This simplifies data preparation and replication of assessment metrics, contributing to the progress of the LLM field.
Unitxt: A Vital Data Backbone for Modern LLM Training
Modern LLM training frameworks demand access to extensive datasets spanning diverse disciplines and languages to achieve state-of-the-art performance. To enable instruction-following, a variety of prompt formulations and verbalizations are essential. However, integrating textual representations from diverse data sources presents substantial technical challenges. Data augmentation, multitask learning, and few-shot tuning become daunting tasks without a common underlying foundation. Unitxt emerges as a crucial data backbone, streamlining the integration of different datasets. With Unitxt, you can effortlessly implement model-specific formatting, data augmentations, dynamic prompt generation, and dataset updates while adhering to a standardized format. This empowers academics to focus on developing secure, robust, and high-performing LLMs without the burden of data wrangling. Numerous teams at IBM engaged in various natural language processing (NLP) activities have already leveraged Unitxt as an indispensable utility for tasks including classification, extraction, summarization, generation, question answering, code analysis, and addressing biases.
Unitxt in Action: Empowering LLM Development
Unitxt has already played a pivotal role in training and evaluating large language models at IBM. The team behind Unitxt envisions a future where this library becomes an integral part of the LLM development process, supported by the open-source community. By unifying textual data processing, Unitxt paves the way for accelerated progress toward more capable, reliable, and trustworthy LLMs, all while emphasizing collaboration, reproducibility, and adaptability. The future of LLM textual data processing is here, and it’s called Unitxt.
Conclusion:
Unitxt represents a significant leap in the field of natural language processing, offering a versatile platform that streamlines text data processing for generative language models. Its emphasis on collaboration, adaptability, and integration with existing workflows positions it as a valuable asset in the evolving market of AI-driven language models and data processing solutions.