
- Large capacity models like LLMs and LMMs excel across domains but suffer from reduced inference speed as parameter count increases.
- Sparse Mixtures of Experts (SMoE) offer scalability but face challenges of low expert activation and limited analytical capabilities.
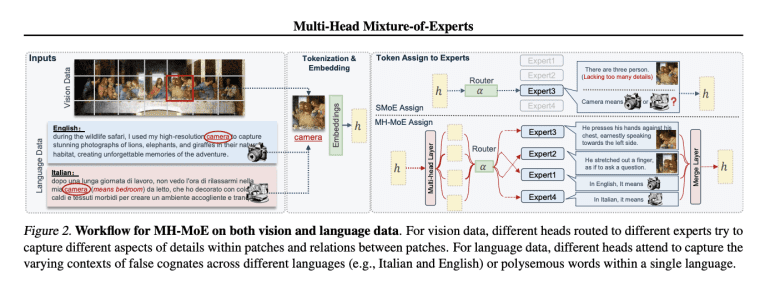
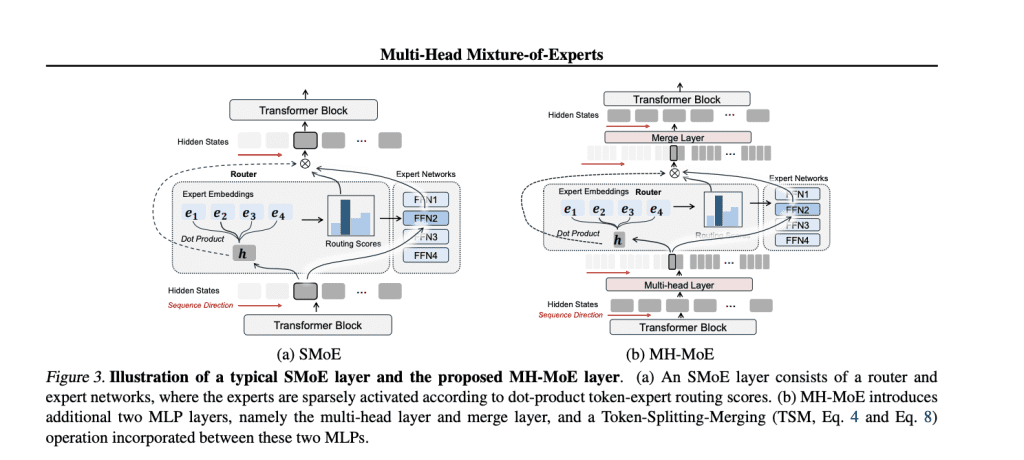
- Multi-Head Mixture-of-Experts (MH-MoE) introduces a multi-head mechanism, activating four experts per input token without added complexity.
- MH-MoE’s architecture employs token splitting and merging operations to enhance expert activation and maintain input-output shape consistency.
- Validation studies demonstrate MH-MoE’s superiority in reducing perplexity across various pre-training tasks and expert configurations.
- MH-MoE outperforms baselines in English-focused and multi-lingual language modeling, as well as in masked multi-modal tasks like visual question answering and image captioning.
Main AI News:
The realm of large capacity models, from Large Language Models (LLMs) to Large Multi-modal Models (LMMs), has showcased remarkable efficacy across diverse domains and tasks. However, as these models expand in parameter count to bolster performance, they often grapple with diminished inference speed, thereby curtailing practicality. Sparse Mixtures of Experts (SMoE) have emerged as a promising avenue, promising scalability while mitigating computational overheads. Yet, challenges persist, notably low expert activation and constrained analytical capabilities, impeding both efficacy and scalability.
Enter Multi-Head Mixture-of-Experts (MH-MoE), a groundbreaking innovation brought forth by researchers from Tsinghua University and Microsoft Research. MH-MoE introduces a multi-head mechanism to fragment input tokens into multiple sub-tokens, channeling them across various experts. This approach achieves denser expert activation sans the burden of heightened computational or parameter complexity. Unlike its predecessor, MH-MoE strategically activates four experts for a single input token by segmenting it into four sub-tokens. This allocation enables nuanced exploration of diverse representation spaces within experts, fostering a deeper comprehension of vision and language patterns.
At its core, MH-MoE’s architecture tackles the challenges of low expert activation and token ambiguity head-on. Each parallel layer comprises a cohort of N experts, with a multi-head layer orchestrating inputs’ projection followed by token splitting and gating functions to route sub-tokens. The top-k routing mechanism then springs into action, activating experts with the highest scores, with resulting sub-tokens undergoing processing before eventual rearrangement to maintain input-output consistency. This Token-Splitting-Merging (TSM) operation amplifies data volume directed to specific experts, driving denser expert activation and refined understanding without incurring additional computational costs.
Validation perplexity curves across various pre-trained models and tasks, scrutinized under two expert configurations (8 and 32 experts), underscore MH-MoE’s superiority. It consistently charts lower perplexity trajectories compared to baselines, signifying more efficient learning. Moreover, the correlation between increased expert count and reduced perplexity bolsters MH-MoE’s prowess in representation learning. Across diverse pre-training tasks, from English-focused language modeling to multi-lingual language modeling, MH-MoE shines. It not only outperforms baselines but also exhibits superiority in modeling cross-lingual natural language. In masked multi-modal tasks like visual question answering and image captioning, MH-MoE’s dominance persists, evidencing its capacity to encapsulate multifaceted semantic nuances within visual data.
Source: Marktechpost Media Inc.
Conclusion:
The advent of Multi-Head Mixture-of-Experts (MH-MoE) represents a significant leap forward in AI model scalability and performance. Its ability to address challenges of low expert activation and token ambiguity while maintaining computational efficiency positions MH-MoE as a frontrunner in the field. As MH-MoE continues to outperform baselines across a spectrum of tasks and configurations, it is poised to drive innovation and set new standards in the AI market. Businesses leveraging MH-MoE can expect enhanced model efficacy and improved performance, paving the way for transformative applications across industries.