
TL;DR:
- AI-driven text-to-video generation has evolved significantly, with a focus on creating concise, narrative-rich movies.
- VideoDirectorGPT, a groundbreaking framework, leverages Large Language Models (LLMs) like GPT-4 to address multi-scene video production challenges.
- The framework comprises two stages: video planning and video generation, seamlessly integrating LLMs.
- VideoDirectorGPT offers precise control over layouts, movements, and visual consistency across scenes.
- It competes effectively with leading models in single-scene text-to-video generation and adapts to user-provided images.
Main AI News:
In the ever-evolving landscape of Artificial Intelligence and Machine Learning, significant strides have been made in the realms of text-to-image and text-to-video generation. While text-to-image conversion is already a remarkable feat, text-to-video (T2V) generation takes it a step further by crafting concise movies, typically consisting of 16 frames at a cinematic two frames per second, all based on textual prompts. This rapidly expanding field has witnessed numerous breakthroughs, especially in the domain of extended video generation, where the objective is to create narrative-rich films spanning several minutes.
However, one inherent challenge when crafting lengthy cinematic experiences is the tendency to include repetitive patterns or sustained actions, which often lack the dynamism and transitions needed for compelling storytelling. Large Language Models (LLMs), such as the formidable GPT-4, have demonstrated their prowess in addressing this challenge, particularly in the context of image generation. These LLMs exhibit an impressive ability to manipulate visual elements with precision and sophistication.
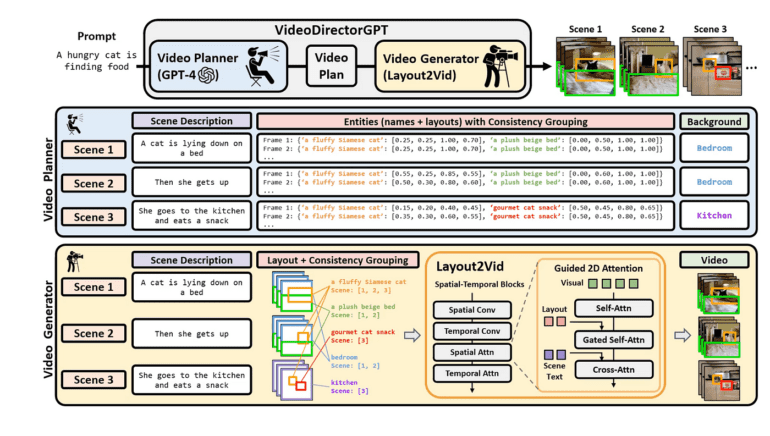
Leveraging the vast knowledge embedded within these LLMs to facilitate the creation of coherent multi-scene videos has been a pressing inquiry among researchers. In a recent breakthrough, a team of dedicated researchers unveiled VideoDirectorGPT, an innovative framework that harnesses the immense potential of LLMs to tackle the complex task of consistently producing multi-scene videos. This framework ingeniously integrates LLMs into the video creation process, offering a holistic solution.
The architecture of VideoDirectorGPT is organized into two pivotal stages. First, the video planning phase employs an LLM to formulate a comprehensive video blueprint, encompassing the overall structure of the video. This blueprint includes multiple scenes with detailed text descriptions, entity names, layouts, and background settings. Importantly, it also outlines consistency groups, specifying which objects or backgrounds should maintain visual coherence across various scenes.
Creating the video plan unfolds in two sequential steps. Initially, the LLM is tasked with transforming a single text prompt into a series of scene descriptions, replete with elaborate explanations, a roster of entities, and background settings. Furthermore, the LLM is called upon to furnish additional details for each entity, encompassing aspects like color and attire, as well as to seamlessly transition entities across frames and scenes. Subsequently, in the second step, the LLM generates a roster of bounding boxes for the entities in each frame, based on the provided entity list and scene descriptions, thereby expanding upon the intricate layouts for each scene. This meticulous video plan serves as a roadmap for the subsequent video production phase.
In the second stage, VideoDirectorGPT employs a specialized video generator known as Layout2Vid, building upon the foundation laid by the video planner. This video generator excels in preserving the temporal consistency of entities and backgrounds across multiple scenes, offering explicit control over spatial layouts. Remarkably, Layout2Vid accomplishes this feat without necessitating extensive video-level training, as it has been exclusively trained with image-level annotations. Experiments conducted with VideoDirectorGPT have yielded remarkable results across various dimensions of video generation, highlighting its efficacy:
- Layout and Movement Control: The framework significantly elevates the level of control over layouts and movements, both in single-scene and multi-scene video generation.
- Visual Consistency Across Scenes: It excels in producing multi-scene videos that maintain visual coherence throughout diverse scenes.
- Competitive Performance: VideoDirectorGPT competes admirably with state-of-the-art models in open-domain single-scene text-to-video generation.
- Dynamic Layout Control: The framework boasts the capability to dynamically adjust the strength of layout guidance, enabling the creation of videos with varying degrees of control.
- User-Provided Images: VideoDirectorGPT showcases its versatility by seamlessly incorporating user-provided images, demonstrating its adaptability and potential for innovative applications.
Conclusion:
VideoDirectorGPT represents a leap forward in the multi-scene video generation market. By harnessing the power of LLMs, it addresses challenges related to visual coherence, layout control, and narrative depth. This innovation promises to unlock new creative possibilities and efficiency in video production, making it a valuable asset for content creators and businesses seeking dynamic text-to-video solutions. As the technology matures, we can expect a transformative impact on industries relying on video content, from entertainment to marketing and beyond.