
TL;DR:
- NExT-GPT is a cutting-edge open-source multimodal AI model.
- It processes text, images, audio, and video for more immersive interactions.
- Developed collaboratively by NUS and Tsinghua University.
- Offers “any-to-any” input and output flexibility.
- Empowers users for customization and dramatic improvements.
- Utilizes modality-switching instruction tuning for seamless transitions.
- Efficient design, training only 1% of total parameters.
- Represents an open source alternative amidst tech giants’ multimodal AI offerings.
Main AI News:
In today’s ever-evolving tech landscape, where industry titans like OpenAI and Google have long held sway, a formidable contender is emerging from the shadows. NExT-GPT, an open-source multimodal AI large language model (LLM), is poised to take on the giants and redefine the AI game.
ChatGPT once captivated the world with its prowess in comprehending natural language queries and crafting human-like responses. However, the relentless pace of AI advancement has ignited a thirst for more. The era of text-only AI is now a relic of the past, making way for the era of multimodal LLMs.
Born from a collaborative effort between the National University of Singapore (NUS) and Tsinghua University, NExT-GPT is a technological marvel capable of processing and generating a medley of text, images, audio, and video. This versatility enables it to offer a far more nuanced and immersive experience than its text-exclusive counterpart, the basic ChatGPT tool.
The brainchild of its creators, NExT-GPT is pitched as an “any-to-any” system, meaning it can seamlessly ingest inputs in any modality and deliver responses in a format tailored to the context. The potential for rapid advancement is monumental. Being open source, NExT-GPT is malleable in the hands of users, allowing for customization that could lead to revolutionary enhancements, akin to the transformation witnessed with Stable Diffusion.
Democratizing access to NExT-GPT empowers creators to mold the technology according to their precise requirements, thus maximizing its impact. But how does this marvel of AI technology operate, you may wonder?
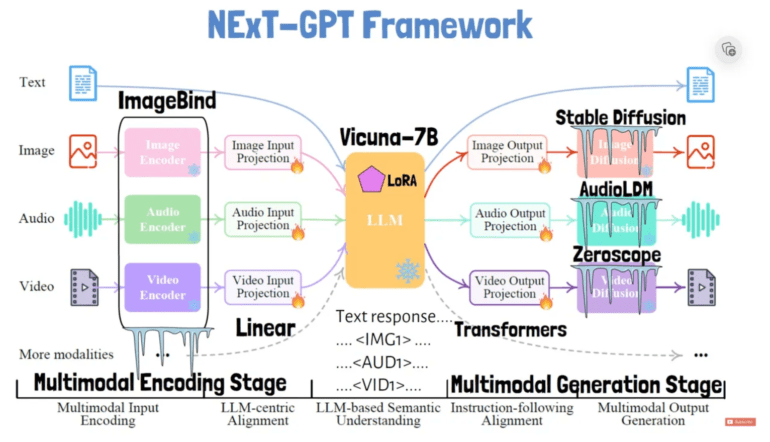
In the model’s research paper, the process is elucidated. NExT-GPT employs discrete modules to encode diverse inputs, such as images and audio, into text-like representations that the core language model can seamlessly digest. The secret sauce lies in a technique known as “modality-switching instruction tuning,” a critical upgrade that endows the model with the ability to seamlessly navigate between different input types during conversations.
To handle these inputs, NExT-GPT utilizes unique tokens dedicated to specific modalities, such as images, audio, and video. Each input type is transformed into embeddings, a language model’s preferred format for understanding. Furthermore, the model can generate response text, accompanied by specialized signal tokens that trigger content generation in other modalities.
For instance, a token embedded in the response instructs the video decoder to craft a corresponding video output. This ingenious use of tailored tokens for each input and output modality affords an unparalleled degree of flexibility, enabling a smooth “any-to-any” conversion.
The language model deploys additional special tokens to indicate when non-text outputs, like images, should be generated. Distinct decoders are then activated to create outputs for each modality. These decoders include Stable Diffusion for images, AudioLDM for audio, and Zeroscope for video. Vicuna serves as the base LLM, while ImageBind is tasked with encoding the inputs.
In essence, NExT-GPT emerges as a powerhouse that amalgamates the strengths of various AI technologies, evolving into an all-encompassing super AI.
Remarkably, NExT-GPT accomplishes this remarkable “any-to-any” conversion while training only 1% of its total parameters. The remainder of the parameters remain frozen, hailing this design as highly efficient—an accolade bestowed by its creators.
Conclusion:
NExT-GPT’s emergence signifies a paradigm shift in the AI market. Its ability to seamlessly handle various data modalities and adapt to users’ specific needs not only enhances user experiences but also democratizes AI technology. This open-source model opens doors for innovation, challenging established tech giants by providing a versatile alternative for creators and businesses looking to harness the power of multimodal AI in their products and services. As the demand for natural interactions continues to rise, NExT-GPT positions itself as a formidable player in shaping the future of AI.