
TL;DR:
- Parallel Speculative Sampling (PaSS) redefines speculative sampling by enabling simultaneous token drafting with a single model.
- PaSS surpasses autoregressive generation and baseline methods in speed and performance.
- It eliminates the need for a second model, enhancing efficiency in natural language processing.
- PaSS introduces parallel decoding, maintaining model quality while achieving remarkable speed.
- PaSS accelerates language model generation by up to 30% without compromising performance.
- The method generates tokens with lower variance and higher predictability.
- Ongoing research aims to further improve PaSS through look-ahead enhancements.
Main AI News:
In a groundbreaking collaboration between EPFL researchers and tech giant Apple, a revolutionary advancement in language model efficiency and scalability has emerged: Parallel Speculative Sampling (PaSS). This cutting-edge approach redefines the landscape of speculative sampling, enabling the simultaneous drafting of multiple tokens using a single model while seamlessly combining the strengths of auto-regressive generation and speculative sampling. PaSS has undergone rigorous testing on text and code completion tasks, delivering remarkable performance gains without any compromise on model quality. Moreover, the research team has delved into the optimal number of look-ahead embeddings, shedding light on the path to optimal results.
Overcoming the Limits of Speculative Sampling
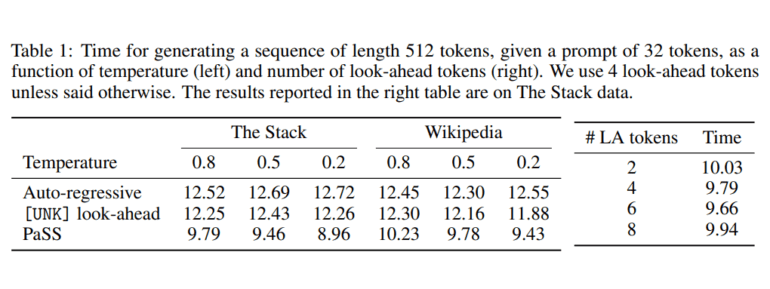
Traditional speculative sampling solutions have long grappled with the requirement of employing two models with identical tokenizers, leading to inevitable bottlenecks in efficiency. Enter PaSS, the game-changer that eliminates the need for a second model while achieving parallel token drafting. Comparative evaluations against autoregressive generation and a baseline method have conclusively demonstrated PaSS’s superior speed and performance in action. Whether tested in the realm of text or code completion tasks, PaSS consistently delivers promising results without compromising the overall excellence of the model. Notably, it offers a fresh perspective on the impact of sampling techniques and look-ahead embeddings, enriching the landscape of language model development.
A Paradigm Shift in Language Model Processing
Large language models have faced inherent limitations in natural language processing, primarily due to the auto-regressive generation approach. This method demands a forward pass for each token generated, causing memory access and processing time challenges. Speculative sampling appeared as a solution but came with its own set of hurdles, necessitating the use of two models with identical tokenizers. PaSS rises to the occasion by enabling the simultaneous drafting of multiple tokens using a single model.
Parallel Decoding: The Heart of PaSS
At the core of the PaSS methodology lies parallel decoding, a concept that removes the necessity for a second model. This innovative approach operates in two distinct phases: drafting and validation. During the drafting phase, the model concurrently generates multiple tokens through parallel decoding, with the first token reserved for distribution matching in the event of rejection. This approach not only delivers remarkable speed and performance enhancements but also upholds the overall quality of the model.
A New Era of Efficiency
The empirical evidence is resounding – the PaSS method significantly accelerates language model generation, boasting an impressive speed-up of up to 30% when compared to auto-regressive generation. Remarkably, this acceleration is achieved without any compromise on model performance. PaSS also shines when it comes to token generation, offering lower variance and higher predictability compared to baseline methods employing different sampling techniques. The study further underlines the influence of look-ahead steps on PaSS performance, with up to a 6-step reduction in running time.
Towards Unprecedented Performance
PaSS stands as a formidable technique in the realm of language model generation, harnessing the power of parallel drafting and fine-tuned look-ahead embeddings. Its ability to produce tokens with minimal variance and high predictability has been resoundingly proven across text and code completion tasks. The horizon of improvement is not far off, with ongoing efforts focusing on look-ahead enhancements to elevate performance even further.
Charting the Path Forward
Future research endeavors are poised to explore methods for enhancing the quality of parallel generation through look-ahead tokens, a promising avenue for further elevating PaSS’s performance. The researchers stress the importance of delving deeper into the impact of the number of look-ahead steps on PaSS, recognizing that an increased number of steps may hold the key to unlocking even greater benefits in this groundbreaking approach.
Conclusion:
The introduction of Parallel Speculative Sampling (PaSS) marks a significant leap in language model efficiency and scalability. Its ability to eliminate the need for a second model while achieving superior speed and performance holds great promise for the market, especially in industries relying heavily on natural language processing. PaSS’s potential to accelerate language model generation by up to 30% while maintaining high-quality output positions it as a game-changer in the field, opening new avenues for enhanced efficiency and productivity.