
TL;DR:
- ReLoRA is a novel method for training massive neural networks more efficiently.
- It uses low-rank updates to achieve high-rank network performance, reducing prohibitive training costs.
- The approach supports overparameterization and addresses resource-intensive neural networks.
- Researchers developed ReLoRA in collaboration with the University of Massachusetts Lowell, Eleuther AI, and Amazon.
- It optimizes training by employing full-rank warm starts, parameter merging, optimizer resets, and learning rate adjustments.
- ReLoRA delivers comparable performance to traditional training, saves up to 5.5GB of RAM per GPU, and accelerates training by 9-40%.
- Qualitative analysis shows a more substantial distribution mass between 0.1 and 1.0, enhancing its efficiency.
Main AI News:
As the field of machine learning advances, the trend toward larger neural networks with ever-increasing parameters continues to gain momentum. However, the rising cost of training these massive networks has become a significant bottleneck in AI research and development. While the success of overparameterized models is undeniable, it’s crucial to gain a deeper understanding of why they are essential and how to optimize their training efficiency.
A groundbreaking solution has emerged from the collaborative efforts of researchers at the University of Massachusetts Lowell, Eleuther AI, and Amazon. They’ve introduced ReLoRA, a revolutionary method that harnesses the power of low-rank updates to train high-rank neural networks efficiently. ReLoRA achieves a high-rank update, delivering performance comparable to conventional neural network training while mitigating the prohibitive costs associated with it.
Scaling laws in AI research have revealed a robust power-law relationship between network size and performance across various domains. This finding underscores the significance of overparameterization and resource-intensive neural networks. However, the Lottery Ticket Hypothesis offers an intriguing alternative perspective, suggesting that overparameterization can be minimized.
To address these challenges, researchers have developed low-rank fine-tuning techniques like LoRA and Compacter, aiming to overcome the limitations of traditional low-rank matrix factorization approaches.
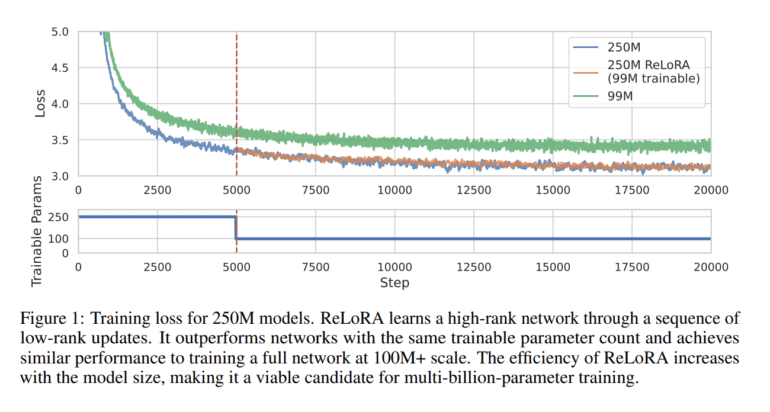
ReLoRA’s transformative capabilities shine when applied to training transformer language models boasting up to 1.3 billion parameters. It consistently delivers performance on par with regular neural network training. The ReLoRA method capitalizes on the rank of the sum property, enabling the training of high-rank networks through a series of low-rank updates. This approach includes a full-rank training warm start before transitioning to ReLoRA, periodic parameter merging into the network’s primary parameters, optimizer resets, and learning rate re-warm up. The implementation also incorporates the Adam optimizer and a jagged cosine scheduler, further enhancing its efficiency.
In empirical comparisons, ReLoRA stands shoulder to shoulder with traditional neural network training in both upstream and downstream tasks. Its impact extends beyond performance, as it optimizes memory usage, saving up to 5.5 gigabytes of RAM per GPU, and accelerates training speeds by an impressive 9-40%, depending on the model size and hardware configuration. A qualitative analysis of the singular value spectrum reveals that ReLoRA exhibits a more substantial distribution mass between 0.1 and 1.0, reminiscent of full-rank training, in stark contrast to LoRA, which predominantly features zero distinct values.
Conclusion:
The introduction of ReLoRA represents a significant advancement in the training of massive neural networks, offering improved efficiency and cost-effectiveness. This innovation has the potential to reshape the AI market by enabling more organizations to leverage large neural networks for enhanced performance while managing the associated training costs effectively. It positions AI researchers and practitioners to explore new frontiers in AI applications with greater ease and affordability.