
TL;DR:
- Mixture-of-Experts (MoE) neural network architecture combines insights from expert networks for complex tasks.
- Sparsely-gated MoE models enhance efficiency with selective activation of model parameters.
- Striking a balance between performance and efficiency is challenging; Sparse MoEs offer a solution.
- Apple’s sparse Mobile Vision MoEs downsize Vision Transformers while maintaining remarkable performance.
- Semantic super-classes guide router training and reduce the number of activated experts per image.
- Empirical results show impressive top-1 accuracy on ImageNet-1k classification benchmark.
- Future plans involve extending MoE design to other mobile-friendly models and exploring object detection.
- Quantifying on-device latency is a priority.
Main AI News:
In the realm of neural network architecture, the Mixture-of-Experts (MoE) framework has emerged as a powerful paradigm. This ingenious approach amalgamates the insights of various expert neural networks, addressing intricate tasks where specialized knowledge is paramount. The inception of MoE models ushered in a new era, fortifying neural networks’ capabilities and empowering them to navigate a multitude of challenging endeavors.
Furthermore, an evolution in neural network architecture, known as sparsely-gated Mixture-of-Experts (MoE) models, builds upon the foundation of conventional MoEs by introducing a novel element—sparsity within the gating mechanism. These ingenious models have been meticulously crafted to enhance the efficiency and scalability of MoE designs, making them adept at tackling large-scale projects while curtailing computational expenses.
The distinguishing feature of sparsely-gated MoE models lies in their ability to selectively activate only a fraction of the model parameters for each input token. This revolutionary characteristic effectively disentangles model size from inference effectiveness, a critical stride toward achieving optimal efficiency.
However, in the realm of neural networks, the perpetual challenge remains to strike the elusive balance between performance and efficiency, particularly in resource-constrained scenarios. Enter sparsely-gated Mixture-of-Experts models, or sparse MoEs, as a potential panacea. These models, with their knack for divorcing model size from inference efficiency, have emerged as a beacon of hope in this landscape of computational constraints.
Sparse MoEs offer the tantalizing prospect of elevating model capabilities while concurrently minimizing computational overhead. This proposition positions them as ideal candidates for integration with Transformers, the reigning choice for large-scale visual modeling.
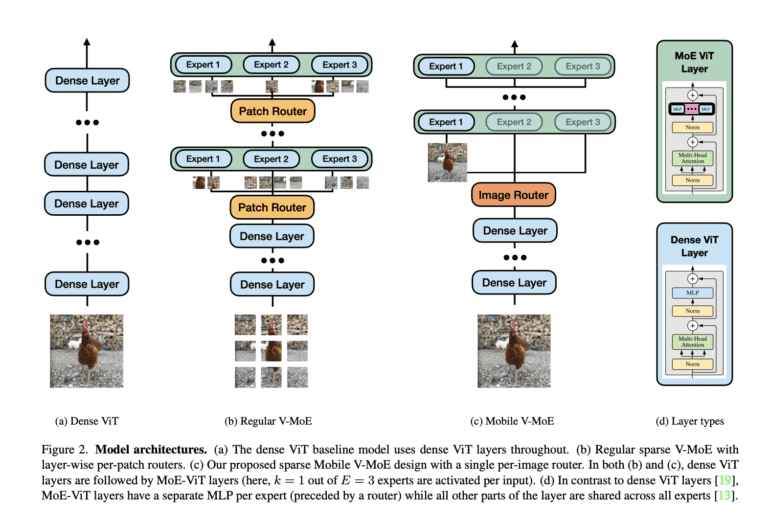
In light of this, an enterprising research team at Apple has introduced a groundbreaking concept: sparse Mobile Vision MoEs. Their pioneering paper, titled “Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts,” presents a compelling solution. These V-MoEs represent an efficient and mobile-friendly Mixture-of-Experts design, capable of preserving exceptional model performance while gracefully downsizing Vision Transformers (ViTs).
The research team’s innovative approach centers around a streamlined training procedure that deftly sidesteps expert imbalance. Their secret weapon? Semantic super-classes, strategically harnessed to guide router training. Unlike traditional per-patch routing, which often activates multiple experts for each image, their per-image router efficiently reduces the number of activated experts per image.
The journey begins with the training of a baseline model, whose predictions are meticulously recorded on a validation set held in reserve from the training dataset. This data forms the bedrock for constructing a confusion matrix, subsequently subjected to a graph clustering algorithm. This process gives birth to super-class divisions, a key component of the team’s strategy.
The empirical results, as presented by the researchers, are nothing short of impressive. They conducted exhaustive training, starting from scratch, on the ImageNet-1k training set, boasting a staggering 1.28 million images. The models’ mettle was then put to the test, evaluating their top-1 accuracy on a validation set comprising 50,000 images.
Looking ahead, the researchers harbor ambitious plans. Their vision extends beyond Vision Transformers (ViTs) to encompass a broader spectrum of mobile-friendly models. Object detection, among other visual tasks, has piqued their interest. Additionally, they are steadfast in their determination to quantify on-device latency across all models, underlining their commitment to ushering in a new era of efficiency in the world of vision transformers.
Conclusion:
The emergence of sparse Mobile Vision MoEs presents a game-changing solution for resource-constrained applications. By effectively decoupling model size from inference effectiveness, these models offer remarkable efficiency gains. Apple’s pioneering efforts in this field have the potential to reshape the market for large-scale visual modeling, making efficient AI solutions more accessible and cost-effective for a wide range of applications.