
TL;DR:
- Advanced large language models face challenges in solving mathematical problems.
- LLMs show potential in solving math problems with multiple attempts.
- PaLM 2-L achieves 33.4% accuracy in math problem solving.
- Researchers focus on improving LLMs’ ability to distinguish between correct and incorrect solutions.
- Three fine-tuning techniques were explored: SSFT, SCR, and Sequential Multi-Tasking Fine-Tuning.
- Experimentation with PaLM 2-S* and PaLM 2-L reveals the significance of well-structured solutions.
- Selective reranking of common solution clusters enhances performance and efficiency.
- Multi-task sequential fine-tuning proves superior in improving solution generation.
Main AI News:
In the realm of advanced large language models (LLMs), including the likes of GPT-4 and PaLM 2, tackling mathematical challenges has long been a formidable task, demanding a fusion of creativity, mathematical acumen, and computational prowess. The uphill climb to finding a valid solution becomes less arduous when these LLMs are granted multiple attempts to surmount the problem. As a result, LLMs have shown substantial promise in rising to the occasion of arithmetic problem-solving. Take, for example, the pre-trained PaLM 2-L, which can achieve an accuracy rate of approximately 33.4% through greedy decoding. However, the true revelation lies in the fact that when subjected to 64 solution samplings using temperature sampling, there exists at least one correct answer (pass@64), an astounding 79.4% of the time.
This performance asymmetry underscores a fundamental challenge: while LLMs exhibit the potential to generate accurate solutions, they grapple with the intricate task of distinguishing between the correct and incorrect ones. To bridge this chasm in performance, researchers have delved into task-specific fine-tuning techniques, aimed at bolstering an LLM’s prowess in both solution development and evaluation.
Within this context, three fine-tuning methodologies come under scrutiny:
- Supervised Step-by-Step Solution Fine-Tuning (SSFT): This approach investigates whether pre-trained LLMs can benefit from an initial supervised fine-tuning phase. Here, LLMs are calibrated to provide comprehensive solutions and answers.
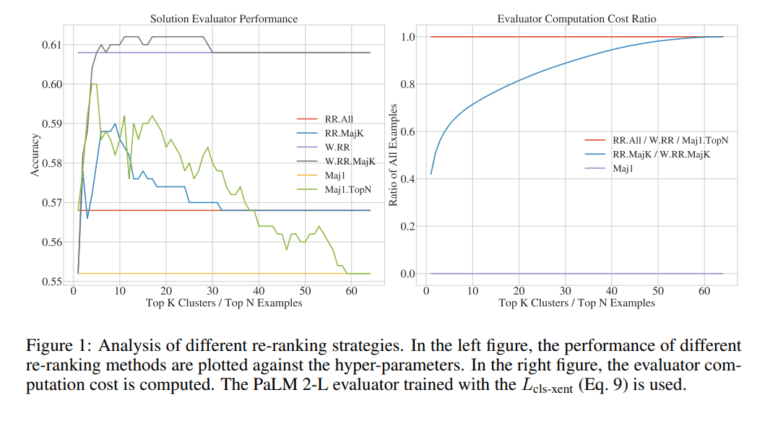
- Solution-Cluster Reranking (SCR): In a quest to refine the LLM’s ability to assess solutions, SCR takes center stage. Unlike previous methods, SCR combines the strengths of majority voting with reranking while simultaneously reducing ranking costs. This involves initially categorizing candidate responses based on mathematical equivalence and then subjecting the most common clusters to the solution evaluator for further enhancement.
- Sequential Multi-Tasking Fine-Tuning: Beyond the solution assessment task, researchers explore enhancing the LLM’s performance in generating solutions. By framing the solution assessment task as a natural language generation problem, they tap into its training objective as a valuable signal for the solution generation model. The model undergoes a three-stage transformation: first as a generator (SSFT), then as a solution evaluator (SCR), and finally, once more as a generator (SSFT).
Through rigorous experimentation employing PaLM 2-S* and PaLM 2-L, the compact and expansive iterations of PaLM 2, on the challenging MATH dataset, the following insights emerge:
- Fine-Grained Solutions Matter: SSFT benefits significantly from well-structured, detailed solutions, emphasizing that the caliber and style of step-by-step solutions wield substantial influence over the refined model.
- Selective Reranking Yields Efficiency: Reranking the most prevalent solution clusters not only elevates performance but also enhances computational efficiency. This approach holds the promise of becoming the standard practice for future endeavors.
- Multi-Task Sequential Fine-Tuning Triumphs: The study underscores the advantages of training the model to excel in both solution generation and evaluation tasks. Leveraging the learning signal of a binary evaluation task for a generation model proves to be a fruitful endeavor. The proposed multi-task sequential fine-tuning emerges as a more potent catalyst for enhancing the performance of the solution generation model, outstripping supervised solution fine-tuning in its efficacy.
Conclusion:
These advanced fine-tuning techniques unlock the potential for large language models to excel in mathematical problem-solving. This breakthrough has far-reaching implications for the market, particularly in AI-driven applications requiring mathematical reasoning, such as finance, data analysis, and engineering. Improved accuracy and efficiency in solving complex math problems will undoubtedly drive innovation and efficiency across various industries.