
TL;DR:
- Large Language Models (LLMs) like ChatGPT have transformed natural language processing.
- LLMs excel in text generation, sentiment analysis, translation, and question-answering.
- Multi-modal integration expands LLMs beyond text, with potential in images, videos, speech, and audio.
- BuboGPT pioneers visual grounding, connecting visual elements and linguistic cues.
- BuboGPT’s pipeline employs tagging, grounding, and entity-matching modules for multi-modal understanding.
- Two-stage training combines audio, vision, and LLMs for enhanced understanding.
- BuboGPT curates high-quality datasets for vision and audio alignment, bolstering multi-modal capabilities.
Main AI News:
In the dynamic arena of natural language processing, Large Language Models (LLMs) have truly disrupted the landscape, evolving into indispensable tools. Among these giants, the ChatGPT stands as a household name, its impact resonating far and wide, infiltrating our daily interactions.
The defining hallmark of LLMs lies in their vast expanse and their ability to glean insights from colossal troves of textual data. This reservoir of knowledge empowers them to fabricate text that mirrors human-like coherence and contextuality. Rooted in sophisticated deep learning architectures like GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers), these models harness attention mechanisms to fathom intricate linguistic nuances, even spanning great lengths.
Harnessing the alchemy of pre-training on sprawling datasets and the finesse of task-specific fine-tuning, LLMs have displayed astonishing prowess across an array of language-centric domains, spanning text generation, sentiment analysis, machine translation, and question-answering. As their prowess continues its upward trajectory, the prospect of revolutionizing natural language comprehension and generation, thereby bridging the gap between mechanized systems and human-like linguistic faculties, gleams ever brighter.
Yet, even amidst this remarkable narrative, some discerning minds pondered whether LLMs could attain greater heights. While their dominion extended over textual inputs, the prospect of broader horizons beckoned. And so, a paradigm shift unfurled—tireless efforts converged to extend LLMs beyond language’s confines. Merging these linguistic juggernauts with varied input signals—images, videos, speech, and audio—engendered the rise of multi-modal chatbots of unprecedented potency.
Yet, within this tapestry of progress, gaps persist. Many of these multimodal sentinels grapple with comprehending the intricate symphony between visual elements and their multidimensional counterparts. While their textual tapestries may exude splendor, they remain entwined in a shroud of opacity, the visual narrative often disjointed from the textual opus.
Enter BuboGPT, a pioneering endeavor heralding a new era of LLMs—a union of text and visual domains forged by the crucible of visual grounding. BuboGPT’s audacious pursuit aspires to weave together the intricate web of visual and linguistic cues. The resulting amalgamation facilitates a harmonious interplay between text, vision, and audio, all unified within a shared representational realm that harmonizes seamlessly with the foundation of pre-trained LLMs.
Yet, the path to visual grounding is fraught with complexity. Herein lies the cornerstone of BuboGPT’s strategy—a meticulously designed pipeline embellished with self-attention mechanics. This apparatus engineers granular bonds between visual constituents and modalities, unfurling a canvas of nuanced interrelationships.
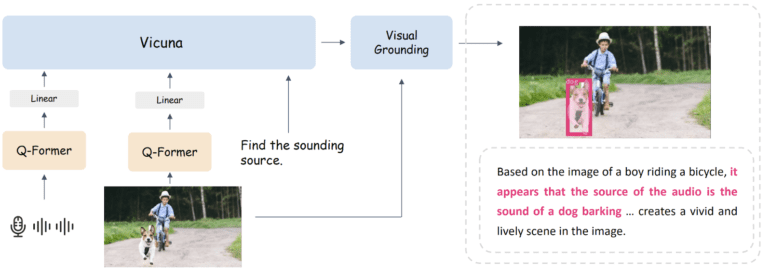
Central to the machinery are three modules: a tagging module, a grounding module, and an entity-matching module. The tagging module conjures pertinent textual descriptors for a given image, while the grounding module conjures semantic masks or boxes, thus pinpointing the spatial essence of each descriptor. Finally, the entity-matching module, employing the acumen of LLM reasoning, orchestrates a symphony of matching between textual and visual constructs.
The outcome of this orchestrated ballet is a vivid fusion of visual components and linguistic cadence. By cementing these liaisons through the medium of language, BuboGPT elevates the comprehension of multi-modal inputs, unfurling a realm of understanding hitherto untapped.
To empower BuboGPT with the prowess to unravel the complexities of eclectic input combinations, a dual-stage training blueprint, akin to the Mini-GPT4 paradigm, comes to the fore. In the initial phase, ImageBind lends its audio-encoding finesse, BLIP-2 lends its vision-encoding prowess, while Vicuna, a peerless LLM, renders its linguistic insights. Together, they construct a Q-former, a linchpin aligning linguistic patterns with audio and visual features. Subsequently, the second stage unfurls—multi-modal instruction tuning, etching the model’s finesse on a high-caliber dataset. A carefully curated repository, encompassing vision, audio, sound localization, and image-audio captioning, propels BuboGPT to a crescendo of multi-modal virtuosity.
Conclusion:
BuboGPT’s breakthrough in visual grounding opens avenues for LLMs to transcend textual confines and comprehend multi-modal inputs. This innovation signifies a paradigm shift in language processing, poised to empower industries to create more immersive and interactive user experiences. The market can anticipate transformative applications in sectors ranging from virtual assistants and content creation to immersive entertainment, thereby reshaping the way humans interact with technology and information.