
- Large multimodal models (LMMs) are reshaping machine understanding of human languages and visual data.
- Multimodal learning requires intricate synthesis of textual and visual inputs.
- Current research emphasizes autoregressive LLMs and fine-tuning with visual data for improved comprehension.
- Small-scale LMMs like TinyLLaVA offer efficient computation and impressive performance.
- TinyLLaVA integrates vision encoders and small-scale LMMs for high-performance multimodal tasks.
- TinyLLaVA-3.1B surpasses larger models like LLaVA-1.5 and Qwen-VL, leveraging vision encoders and small-scale LMMs.
- Shared recipes and fine-tuning enhance overall model effectiveness.
- Smaller LMMs optimized with suitable data and methodologies exhibit promising potential.
Main AI News:
In the realm of machine intelligence, the emergence of large multimodal models (LMMs) has promised a paradigm shift in how machines perceive and interact with human languages and visual data. These models offer a more intuitive avenue for machines to comprehend our world, bridging the gap between textual and visual information seamlessly. However, the complexity lies in effectively synthesizing and interpreting data from disparate modalities to derive meaningful insights.
The ongoing pursuit in multimodal learning has led researchers to explore autoregressive LLMs for vision-language tasks, delving into the realm of understanding visual signals as conditional information. Notably, there’s a growing interest in fine-tuning LMMs with visual instruction tuning data to enhance their zero-shot capabilities. Concurrently, the development of small-scale LMMs such as Phi-2, TinyLlama, and StableLM-2 has gained traction, offering impressive performance while mitigating computational overhead.
A groundbreaking contribution from Beihang University and Tsinghua University in China comes in the form of TinyLLaVA, a novel framework harnessing the power of small-scale LLMs for multimodal tasks. Comprising a vision encoder, a compact LLM decoder, an intermediate connector, and specialized training pipelines, TinyLLaVA sets out to achieve superior performance in multimodal learning while optimizing computational resources.
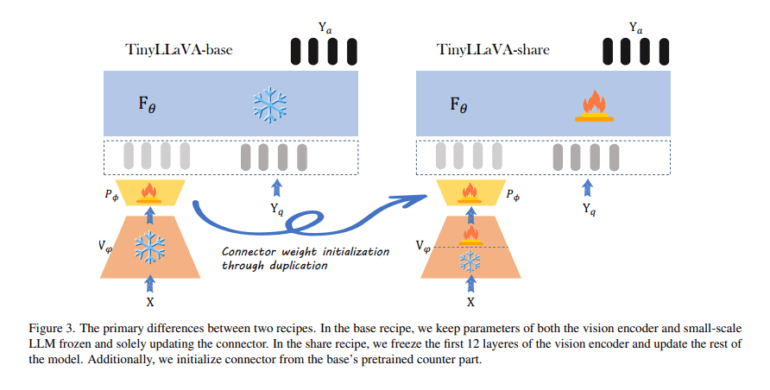
TinyLLaVA introduces a family of small-scale LMMs, with its flagship model, TinyLLaVA-3.1B, surpassing larger 7B models like LLaVA-1.5 and Qwen-VL. By integrating vision encoders such as CLIP-Large and SigLIP with compact LMMs, TinyLLaVA showcases enhanced performance. The training regimen incorporates two distinct datasets, LLaVA-1.5 and ShareGPT4V, to assess the impact of data quality on LMM performance. Notably, it allows for fine-tuning of partially learnable parameters of the LLM and vision encoder during supervised training, offering a comprehensive analysis of model configurations, training methodologies, and data contributions.
Experimental findings underscore the superiority of model variants leveraging larger LLMs and the SigLIP vision encoder. The shared recipe, inclusive of vision encoder fine-tuning, augments the efficacy of all model variants. Noteworthy is the TinyLLaVA-share-Sig-Phi variant, boasting 3.1B parameters, which outshines the larger 7B parameter LLaVA-1.5 model across comprehensive benchmarks. These results underscore the potential of compact LMMs, optimized with suitable data and training strategies, to outperform their larger counterparts.
Conclusion:
The emergence of TinyLLaVA underscores a pivotal shift in machine learning towards compact yet powerful multimodal frameworks. As smaller models like TinyLLaVA-3.1B outshine their larger counterparts, it signifies a market trend towards efficiency without compromising performance. This innovation heralds a new era where businesses can leverage advanced multimodal capabilities without extravagant computational demands, thus democratizing access to cutting-edge AI technologies.