
TL;DR:
- The Vary method enhances Large Vision-Language Models (LVLMs) for specialized, fine-grained perception tasks.
- Developed by researchers from leading institutions, Vary empowers LVLMs to acquire new features efficiently.
- Experimental results demonstrate Vary’s effectiveness in various functions, highlighting its potential in advancing multilingual perception tasks.
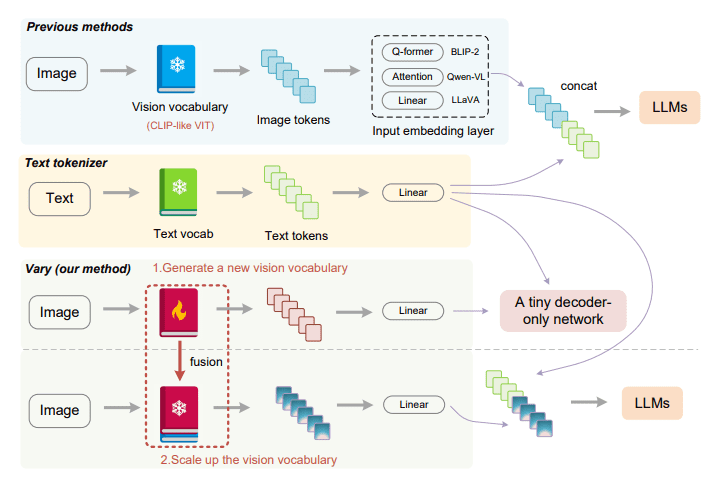
- Vary addresses limitations in common vision vocabularies, motivating the expansion of visual vocabularies in LVLMs.
- Vary introduces two configurations, Vary-tiny and Vary-base, optimizing LVLM performance for different tasks.
- Vary excels in document-level OCR, chart comprehension, and MMVet tasks, showcasing its parsing capabilities.
- Continuous enhancements are needed to scale up visual vocabularies for future market dominance.
Main AI News:
In the realm of cutting-edge Large Vision-Language Models (LVLMs), a groundbreaking approach has emerged to revolutionize the way these models perceive and understand visual content for advanced multilingual tasks. LVLMs have undeniably transformed various applications, from image captioning to visible question answering and image retrieval. Nevertheless, these formidable models confront challenges, particularly when confronted with specialized tasks requiring intricate and nuanced perception.
Enter the Vary method, a pioneering solution developed by researchers from Huazhong University of Science and Technology, MEGVII Technology, and the University of Chinese Academy of Sciences. Vary is poised to elevate LVLMs’ capabilities, enabling them to efficiently acquire new features, thus enhancing fine-grained perception for specialized tasks. Experimental evidence attests to Vary’s remarkable effectiveness across a spectrum of functions, heralding a new era in LVLMs.
Vary stands as a beacon of progress, presenting a platform for further exploration. The researchers have recognized the immense potential of GPT-4 for generating training data, further underlining Vary’s versatility in enhancing downstream visual tasks. While Vary expands LVLM capabilities, it remains firmly anchored in preserving its original strengths.
One of the pivotal aspects addressed by this research is the limitations of common vision vocabularies, exemplified by CLIP-VIT, in the context of dense and fine-grained vision perception scenarios. This limitation serves as a clarion call for the augmentation of visual vocabularies within LVLMs. Vary takes inspiration from expanding text vocabularies in LVLMs for foreign languages and ingeniously applies this concept to vision.
Vary’s core innovation lies in the creation of a new vision vocabulary through a specialized vocabulary network, seamlessly integrated with the original vocabulary. This integration aims to optimize encoding efficiency and model performance, particularly in diverse tasks like non-English OCR and chart comprehension. The introduction of Vary sparks anticipation of further research and innovation in this promising direction.
Within the Vary framework, two distinct configurations emerge: Vary-tiny and Vary-base. Vary-tiny, tailored for fine-grained perception, dispenses with a text input branch and employs the compact OPT-125M model. Its training regimen involves the use of document and chart data as positive samples, juxtaposed with natural images as negatives. The vocabulary network in Vary-tiny operates in tandem with the original vocabulary integrated into Vary-base. During Vary-base training, both vocabulary networks work in harmony, with their weights frozen, while the optimization efforts focus on LVLM parameters and input embedding layers. Implementation details encompass the utilization of AdamW optimization, a cosine annealing scheduler, and meticulously calibrated learning rates. Synthetic data is strategically generated to facilitate document and chart comprehension.
The results speak volumes about Vary’s prowess, as it demonstrates outstanding performance across an array of tasks, excelling in document-level OCR, chart comprehension, and MMVet tasks. Notably, it achieves an ANLS (Average Normalized Levenshtein Similarity) score of 78.2% in DocVQA and 36.2% in MMVet, underlining its proficiency in parsing new document features. In the domain of document OCR tasks, both Vary-tiny and Vary-base deliver robust results, with Vary-base emerging as the standout performer among LVLMs.
Conclusion:
The Vary method represents a significant leap in advancing multilingual vision-language models. Its success in fine-grained perception tasks and the promise it holds for diverse applications, such as OCR and chart understanding, positions it as a potential game-changer in the market. To stay competitive, businesses in the AI and language processing sectors should keep a close eye on developments related to Vary and invest in expanding their own visual vocabularies to meet evolving customer demands.