
- Recent advancements in neural language models showcase the remarkable capabilities of Large Language Models (LLMs) enabled by the Transformer architecture.
- In-context learning (ICL) abilities, traditionally associated with Transformers, have been demonstrated to also exist in multi-layer perceptrons (MLPs) and MLP-Mixer models.
- A study by Harvard researchers compares MLPs and Transformers, revealing competitive performance across ICL tasks, with MLPs excelling in relational reasoning tasks.
- MLPs exhibit resilience and maintain optimal performance under varying context lengths and increased data diversity.
- Comparative analysis highlights Transformers’ slight advantage over MLPs in scenarios with limited computing budgets.
Main AI News:
Recent advancements in neural language models, notably Large Language Models (LLMs) driven by the Transformer architecture and scale expansion, mark a significant leap forward in AI capabilities. These models excel in various linguistic tasks such as text generation, question answering, summarization, creative content generation, and complex problem-solving. A pivotal feature distinguishing these models is their in-context learning (ICL) ability, where they adeptly leverage new task instances during inference without requiring weight updates. Traditionally, this capability has been associated with Transformers and their attention mechanisms.
Studies have showcased Transformers’ prowess in tasks like linear regression, demonstrating their capacity to generalize to new context input and label pairs seamlessly. They achieve this feat through mechanisms akin to gradient descent or by mimicking least-squares regression methods. Moreover, Transformers exhibit a dynamic interplay between in-weight learning (IWL) and ICL, with the richness of datasets further enhancing their ICL capabilities. While much attention has been lavished on Transformers, research diversifies into exploring other architectures like recurrent neural networks (RNNs) and LSTMs, albeit with varying degrees of success. Recent revelations even point to causal sequence models and state space models achieving notable ICL milestones. However, the latent potential of multi-layer perceptrons (MLPs) for ICL remains relatively untapped, despite their resurgence in tackling intricate tasks, spurred on by innovations like the MLP-Mixer model.
In a groundbreaking study conducted by Harvard researchers, the efficacy of multi-layer perceptrons (MLPs) in in-context learning is empirically demonstrated. Surprisingly, MLPs and MLP-Mixer models exhibit competitive performance with Transformers across ICL tasks, all within comparable computational budgets. Notably, MLPs outshine Transformers in tasks requiring relational reasoning, challenging the conventional wisdom that ICL is exclusive to Transformers. This revelation beckons a broader exploration beyond attention-based architectures and hints that Transformers, constrained by their reliance on self-attention and positional encodings, might exhibit biases against certain task structures compared to MLPs.
The study delves into MLPs’ behavior within the realm of in-context learning, scrutinizing two primary tasks: in-context regression and in-context classification. In the case of ICL regression, the model is tasked with predicting a target value yq based on a sequence of input-output pairs (xi, yi), each characterized by varying weights β and added noise, alongside a query xq. The model’s prowess lies in inferring the appropriate β from the context exemplars to predict yq accurately. Meanwhile, in ICL classification, the model faces a sequence of exemplars (xi, yi) followed by a query xq sampled from a Gaussian mixture model. Here, the model’s objective is to assign the correct label to xq by leveraging the contextual information, considering both data diversity and burstiness (the number of repeats per cluster in the context).
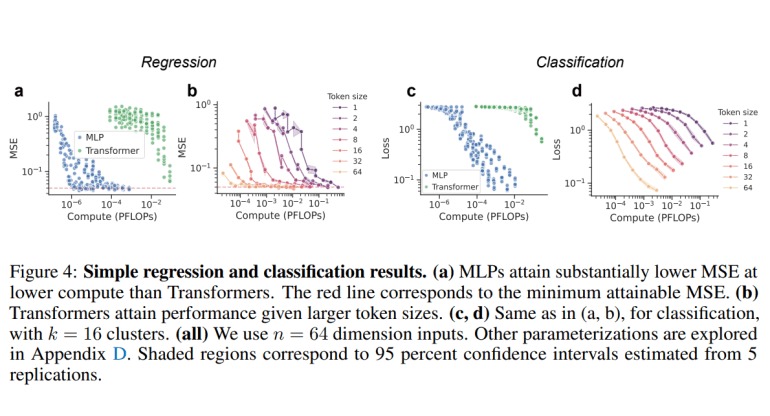
Comparative analysis between MLPs and Transformers on these tasks reveals intriguing insights. Both architectures, including MLP-Mixers, achieve near-optimal mean squared error (MSE) given sufficient computational resources, although Transformers hold a slight edge over MLPs under constrained computing budgets. Notably, vanilla MLPs exhibit deteriorating performance with longer context lengths, whereas MLP-Mixers maintain optimal MSE levels. Furthermore, as data diversity increases, all models exhibit a transition from IWL to ICL, with Transformers showcasing a faster transition rate. In the realm of in-context classification, MLPs perform comparably to Transformers, showcasing consistent loss patterns across context lengths and mirroring the transition from IWL to ICL with escalating data diversity.
Harvard’s meticulous investigation underscores the comparability of MLPs and Transformers in in-context regression and classification tasks. While all architectures, including MLP-Mixers, achieve near-optimal MSE with adequate computational resources, Transformers demonstrate a slight advantage over MLPs, particularly in scenarios with limited computing budgets. However, the resilience of MLPs, especially MLP-Mixers, in maintaining optimal performance under varying context lengths and adapting swiftly to increased data diversity hints at their broader applicability in real-world scenarios. This study not only broadens our understanding of in-context learning capabilities but also paves the way for leveraging diverse neural architectures for addressing complex AI challenges.
Conclusion:
The comparative study between multi-layer perceptrons (MLPs) and Transformers on in-context learning tasks sheds light on the broader applicability of neural architectures in AI. While Transformers hold a slight edge in certain scenarios, MLPs showcase resilience and competitive performance, especially in relational reasoning tasks. This underscores the need for businesses to consider a diverse range of neural architectures to address complex AI challenges effectively.