
TL;DR:
- Large Language Models (LLMs) face challenges of high computational costs and accurate evaluation.
- A novel strategy for LLM development allows cost-effective growth, democratizing access.
- An IQ evaluation benchmark assesses LLM intelligence in symbolic mapping, rule understanding, pattern recognition, and anti-interference ability.
- Achievements include training a 100 billion-parameter LLM on a $100,000 budget, overcoming instability issues, and fostering collaboration through resource sharing.
Main AI News:
In the rapidly evolving landscape of Natural Language Processing (NLP) and multimodal tasks, Large Language Models (LLMs) have emerged as transformative forces. However, they’ve been shackled by two formidable challenges: exorbitant computational expenses and the intricate task of conducting impartial evaluations. These obstacles have confined LLM development to a select few, limiting the scope of research and practical applications within the domain. In response to this critical conundrum, a pioneering strategy has emerged, one that could revolutionize the landscape of LLM development and training.
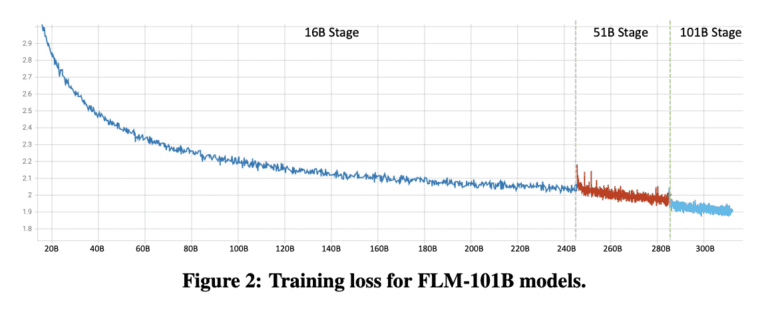
To confront the formidable challenge of training cost, researchers have embarked on a journey to cultivate a 100-billion-parameter LLM through a groundbreaking growth strategy. What sets this strategy apart is its departure from conventional fixed-parameter approaches. Instead, it allows the model’s dimensions to expand progressively, ushering in an era of cost-effective training methods that promise to democratize access to LLM capabilities.
But the question looms: How can we truly measure the intelligence of these colossal language models? To tackle this, a comprehensive IQ evaluation benchmark has been devised, comprising four key facets of intelligence assessment:
- Symbolic Mapping: LLMs are put through their paces, gauging their capacity to generalize across novel contexts using symbolic mappings – akin to human cognition’s reliance on symbols over categorical labels.
- Rule Understanding: The benchmark scrutinizes whether LLMs can grasp and apply established rules, mirroring a fundamental aspect of human intelligence.
- Pattern Mining: LLMs are rigorously tested for their prowess in recognizing patterns, employing both inductive and deductive reasoning – an invaluable skill transcending diverse domains.
- Anti-Interference Ability: This metric measures an LLM’s resilience to external disruptions, highlighting a critical facet of intelligence – the ability to maintain performance amidst interference.
The fruits of this study are manifold, each contributing significantly to the advancement of LLMs:
- Monumental Achievement: The successful training of an LLM with a staggering 100 billion parameters through a cost-efficient growth strategy, all within a budget of a mere $100,000, marks a watershed moment in the field.
- Taming Instabilities: The research has grappled with and triumphed over instability issues that have plagued LLM training. Enhancements in FreeLM training objectives, innovative methods for hyperparameter optimization, and the introduction of function-preserving growth are beacons of hope for the broader research community.
- Rigorous Experimentation: A robust array of experiments, encompassing established knowledge-oriented benchmarks and an innovative systematic IQ evaluation benchmark, has been conducted. These findings enable a meaningful comparison against baseline models, affirming the exceptional and resilient performance of FLM-101B.
- Fostering Collaboration: The research team has generously contributed to the research ecosystem by releasing model checkpoints, code, and an array of valuable resources. These assets are poised to catalyze further exploration within the realm of bilingual Chinese and English LLMs, each harboring over 100 billion parameters.
Conclusion:
The development of FLM-101B represents a significant leap forward in the world of Large Language Models (LLMs). By addressing the cost and evaluation challenges that have limited LLM research and application, this breakthrough strategy promises to democratize access to LLM capabilities. The comprehensive IQ evaluation benchmark further enhances our ability to measure LLM intelligence. Overall, these advancements are poised to reshape the LLM market, making it more accessible and robust for a wide range of applications and industries.