
TL;DR:
- MonoXiver combines 2D-to-3D information flow and Perceiver I/O model for advanced 3D object detection.
- Existing 3D extraction methods from 2D photos are deemed insufficient.
- Cameras, as a cost-effective alternative to LIDAR, play a pivotal role in autonomous vehicle design.
- Current approaches, relying on bounding boxes, fall short in separating 3D data from 2D images.
- MonoXiver takes a unique approach by analyzing the area around bounding boxes for improved accuracy.
- The research evaluates the model’s performance using two diverse datasets, achieving practical utility at 40 frames per second.
- Researchers are committed to refining MonoXiver for optimal effectiveness.
Main AI News:
In the realm of artificial intelligence, a relentless surge of innovation continues to redefine the boundaries of human knowledge. As each day unfolds, AI’s pervasive influence permeates various domains, and one area of particular intrigue is the extraction of 3D data from 2D images. Through rigorous experimentation and research, a groundbreaking model has emerged, poised to revolutionize the capabilities of cameras in the context of these transformative technologies.
According to the insights shared by Tianfu Wu, an esteemed associate professor specializing in electrical and computer engineering at North Carolina State University and a co-author of a notable research publication, the existing methods for extracting 3D information from 2D images, though commendable, are undeniably limited.
In the pursuit of progress, researchers have sought to bridge the gap between two-dimensional (2D) images captured by cameras and the realm of three-dimensional (3D) data. This cost-effective approach stands as a preferred alternative to technologies like LIDAR, which employ laser-based methods for 3D spatial estimation. The affordability and accessibility of cameras enable their widespread integration, providing autonomous vehicle designers with a resilient and redundant system.
However, the true potential of this approach hinges on the ability of AI systems within autonomous vehicles to decipher 3D navigational insights from the 2D images captured by these cameras. Presently employed techniques fall short of this imperative task. Common methodologies employ bounding boxes, exemplified by the MonoCon technique pioneered by Wu and his collaborators. These techniques instruct AI systems to meticulously analyze 2D images, delineating 3D bounding boxes around objects, such as vehicles traversing a city street.
Bounding boxes serve as the cornerstone of artificial intelligence (AI) systems, enabling them to gauge the dimensions of objects within images and comprehend their spatial relationships. These bounding boxes empower AI to estimate the size and position of an object, such as an automobile, relative to its surroundings—a pivotal capability for applications spanning autonomous driving to computer vision systems.
Regrettably, bounding box algorithms confront inherent limitations, frequently failing to encapsulate all constituent parts of a vehicle or other objects depicted within a 2D image. These deficiencies underscore the challenge of achieving precision in object detection, compelling the need for enhancements in bounding box algorithms to bolster accuracy and ensure comprehensive object depiction within 2D imaging.
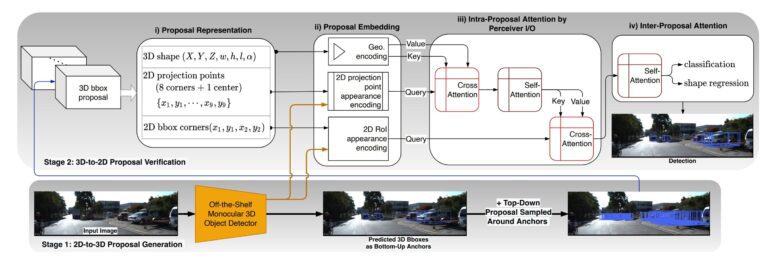
Enter the MonoXiver approach, a paradigm shift in 3D object detection. This innovative method adopts a unique strategy, scrutinizing the vicinity surrounding each bounding box, with each box serving as an anchor point. The evaluation process unfolds through two crucial comparisons. Firstly, it meticulously examines the “geometry” of each secondary box, seeking structural congruence with the anchor box to ensure precise spatial alignment. Subsequently, the method delves into the visual aspects, scrutinizing factors like color and other visual attributes within each secondary box.
In their quest for excellence, the researchers conducted comprehensive evaluations, leveraging two diverse datasets of 2D image data—the renowned KITTI dataset, renowned for its complexity, and the substantial Waymo dataset.
Their findings revealed that while MonoCon operates at an impressive 55 frames per second in isolation, the adoption of the MonoXiver approach does introduce a marginal reduction in speed, slowing down to a still-practical 40 frames per second. The researchers, driven by an unwavering commitment to progress, have expressed their intent to refine and optimize the method further, with meticulous fine-tuning of its parameters, ensuring its unwavering effectiveness in the realm of 3D object detection.
Conclusion:
MonoXiver’s groundbreaking approach to 3D object detection signifies a pivotal moment in the AI technology landscape. By seamlessly merging 2D-to-3D information flow with the Perceiver I/O model, MonoXiver addresses the limitations of existing methods. Its potential to improve the accuracy of object detection in 2D imaging, particularly in the context of autonomous vehicles, opens up new possibilities in the market. As AI-driven technologies continue to shape industries, MonoXiver’s commitment to refinement underscores its potential to be a game-changer in the evolving landscape of artificial intelligence and computer vision.