
TL;DR:
- Music generation using deep generative models has gained significant attention.
- Language models (LMs) and diffusion probabilistic models (DPMs) have shown promise in audio synthesis.
- MeLoDy combines the strengths of LMs and DPMs for efficient text-to-audio conversion.
- The semantic LM captures the structure of music, while DPMs handle acoustic modeling.
- The dual-path diffusion (DPD) model reduces computational expenses by using latent representations.
- MeLoDy aims to strike a balance between generative efficiency and interactive capabilities.
Main AI News:
In today’s fast-paced world, music has become an integral part of our lives, resonating with our emotions and shaping our experiences. As the realm of deep generative models continues to expand, the fascination with music generation has grown exponentially. Language models (LMs), known for their remarkable ability to capture intricate relationships within vast contexts, have paved the way for groundbreaking advancements in audio synthesis. Building upon this foundation, AudioLM and its subsequent innovations have successfully harnessed LMs to create captivating soundscapes.
Simultaneously, diffusion probabilistic models (DPMs), a formidable contender among generative models, have showcased their exceptional proficiency in synthesizing speech, sounds, and even music. However, translating free-form text into harmonious melodies remains a complex endeavor, given the diverse range of music descriptions that span genres, instruments, tempos, scenarios, and subjective sentiments.
Previous text-to-music generation models have primarily focused on specific attributes such as audio continuity or rapid sampling. Some have prioritized rigorous testing, often conducted by industry experts like music producers. Additionally, these models have been trained on extensive music datasets, demonstrating state-of-the-art generative performance with unparalleled fidelity and adherence to various text prompts.
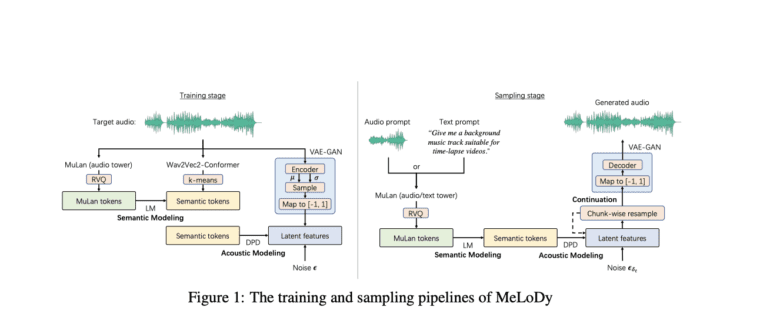
Building on the triumphs of MusicLM, the authors have harnessed the power of its highest-level LM, aptly named semantic LM, to meticulously capture the semantic structure of music. By comprehensively modeling melody, rhythm, dynamics, timbre, and tempo, the semantic LM governs the overall arrangement of musical elements. Capitalizing on the non-autoregressive nature of DPMs, the authors seamlessly integrate acoustic modeling, aided by a highly effective sampling acceleration technique.
Furthermore, a groundbreaking solution termed the dual-path diffusion (DPD) model has been proposed as an alternative to the traditional diffusion process. Recognizing the exponential computational expenses associated with working on raw data, this innovative approach reduces the raw data to a low-dimensional latent representation. By minimizing the data’s dimensionality, the model’s runtime is significantly reduced without compromising its efficacy. The original data can then be reconstructed from the latent representation using a pre-trained autoencoder, ensuring no loss of fidelity.
While the successes of MusicLM and Noise2Music are undeniable, the computational demands they impose hinder their practical implementation. Conversely, alternative approaches based on DPMs have achieved efficient sampling of high-quality music. However, their demonstrated cases have been relatively limited in scale and exhibit restricted in-sample dynamics. To realize a viable music creation tool, striking a balance between generative efficiency and interactive capabilities is crucial, as highlighted in a prior study.
Amidst the impressive results achieved by LMs and DPMs, the question at hand is not which approach should prevail, but rather if it’s feasible to leverage the strengths of both in tandem. This brings us to the development of MeLoDy, an innovative approach designed to combine the advantages of LMs and DPMs. The figure below provides an insightful overview of the MeLoDy strategy, unveiling the path to unlocking the full potential of music synthesis.
Conclusion:
The development of MeLoDy, an efficient text-to-audio diffusion model, represents a significant advancement in the field of music synthesis. By combining the power of language models and diffusion probabilistic models, MeLoDy offers a transformative approach to generating music from text prompts. This innovation opens up new possibilities for musicians, composers, and music enthusiasts by providing a practical and interactive tool for creative expression.
As MeLoDy bridges the gap between generative efficiency and user interactivity, it holds tremendous potential to reshape the market for music generation technologies. Its ability to capture complex relationships and produce high-quality musical compositions positions it as a game-changer in the industry, paving the way for exciting developments in the future. Businesses operating in the music technology sector should closely monitor MeLoDy’s progress and consider integrating its capabilities into their offerings to stay competitive in the evolving market landscape.