
- Large language models (LLMs) face limitations in input length and memory capabilities.
- SirLLM introduces innovations in attention mechanisms and memory retention.
- Utilizes Token Entropy metric and decay mechanism to filter key phrases.
- Outperforms baseline models consistently across diverse tasks.
- Offers robustness and versatility for future NLP applications.
Main AI News:
The burgeoning expansion of large language models (LLMs) has ignited a flurry of advancements in natural language processing (NLP) applications, spanning from chatbots to writing assistants and programming aides. Yet, the inherent limitations of current LLMs, notably their restricted input length and memory capabilities, pose significant hurdles to realizing their full potential. As the demand for NLP solutions with expansive memory spans surges, researchers are delving into novel approaches to empower LLMs to handle infinite input lengths while preserving critical information. Recent endeavors have honed in on optimizing attention mechanisms as a pivotal avenue for extending LLMs’ input context length, ushering in a new era of innovation.
In the pursuit of extending LLMs’ input context length, a plethora of methodologies have emerged, each refining the intricacies of the attention mechanism. Techniques such as Sliding-window attention offer stability in decoding speed by constraining each token to attend solely to recent tokens. Meanwhile, innovations like fixed Sparse Transformer and LogSparse self-attention have been proposed to uphold local context information while augmenting global attention. Notably, StreamLLM has been introduced as a groundbreaking solution, aiming to realize true infinite input length by maintaining focus on both initial and recent tokens. However, prevailing approaches grapple with challenges such as token preservation and memory degradation, necessitating further exploration.
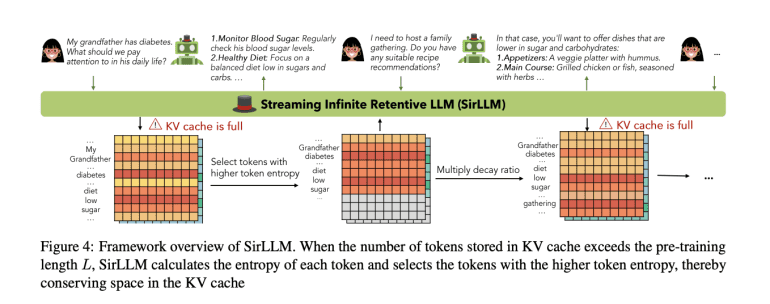
Enterprising researchers from Shanghai Jiao Tong University and Wuhan University unveil Streaming Infinite Retentive LLM (SirLLM), a cutting-edge model engineered to empower LLMs with extended memory capabilities for infinite-length dialogues sans the need for fine-tuning. At the heart of SirLLM lies the integration of the Token Entropy metric and a sophisticated memory decay mechanism, strategically filtering key phrases to bolster LLMs’ endurance and adaptability. To comprehensively evaluate SirLLM’s efficacy, three distinct tasks and corresponding datasets were meticulously curated: DailyDialog, Grocery Shopping, and Rock-Paper-Scissors.
Leveraging entropy values for each token, SirLLM fortifies the model’s memory prowess by judiciously preserving key-value states of pivotal tokens, culminating in its inception. The architectural blueprint of SirLLM revolves around the orchestration of both a key-value (KV) cache and a token entropy cache. When the token count surpasses the pre-training length threshold L within the KV cache, SirLLM employs entropy calculations to identify tokens with heightened significance, thereby optimizing space utilization. This entails the selection of the top k tokens with maximal token entropy, indicative of their informational richness. Moreover, SirLLM strategically adjusts token positions within the cache, prioritizing relative distances over original text positions. However, a sole reliance on entropy-based token preservation risks fostering a rigid memory framework within the model, impeding adaptability. To surmount this challenge, a decay ratio ηdecay, set below 1, is proposed, enabling the model to shed outdated key information post each dialogue round, thus fostering flexibility and enhancing user engagement.
A meticulous examination of the Rock-Paper-Scissors dataset underscores SirLLM’s consistent superiority over the baseline StreamLLM across players with diverse throwing preferences. SirLLM exhibits a sustained enhancement in win rates against players of varied inclinations, maintaining this heightened performance consistently across all evaluated scenarios. The integrated decay mechanism plays a pivotal role in perpetuating balanced performance over successive rounds, as evidenced by uniformly elevated win rates. This attribute proves particularly advantageous in protracted interactions such as extended Rock-Paper-Scissors matches, underscoring SirLLM’s adeptness in adaptability and recall, critical elements for triumph.
Conclusion:
The introduction of SirLLM signifies a monumental stride in addressing the pivotal challenges surrounding infinite input lengths and memory capabilities. SirLLM not only achieves prolonged dialogue retention sans model fine-tuning but also selectively reinforces focus on pivotal information, elevating its utility across diverse tasks. Through empirical validation across a spectrum of tasks including DailyDialog, Grocery Shopping, and Rock-Paper-Scissors, SirLLM consistently exhibits robustness and versatility, poised to spearhead future endeavors in natural language processing.