
TL;DR:
- MIT researchers developed a million-scale synthetic dataset, SyViC, enriched with textual annotations.
- SyViC enhances comprehension of Visual Language Concepts (VLC) and compositional reasoning in vision and language models.
- Innovative methodology fine-tunes models using synthetic data, yielding over 10% improvements in some cases.
- Results were validated across popular benchmarks, demonstrating the efficiency of the approach.
- Limitations include simplified graphics simulation, hinting at the need for further refinement.
- MIT’s work paves the way for AI advancements, addressing critical limitations in existing models.
Main AI News:
In the ever-evolving landscape of artificial intelligence, large-scale pre-trained vision and language models have undoubtedly emerged as game-changers, demonstrating exceptional prowess in various applications. These models have paved the way for a paradigm shift, allowing the replacement of rigid class definitions with the versatility of zero-shot open vocabulary reasoning over natural language queries. However, a critical limitation has recently come to light – the inability of these models to grasp Visual Language Concepts (VLC) that transcend traditional nouns. Concepts like attributes, actions, relations, and states, as well as the nuances of compositional reasoning, have remained elusive to them.
Vision and language models have excelled in tasks like generating video captions and summaries, showing a remarkable ability to identify objects in images. However, their shortcomings become evident when it comes to understanding the finer details, such as the attributes of objects or the spatial arrangement of elements within a scene. For instance, while they can identify a cup and a table in an image, they may struggle to comprehend that the cup is placed on top of the table.
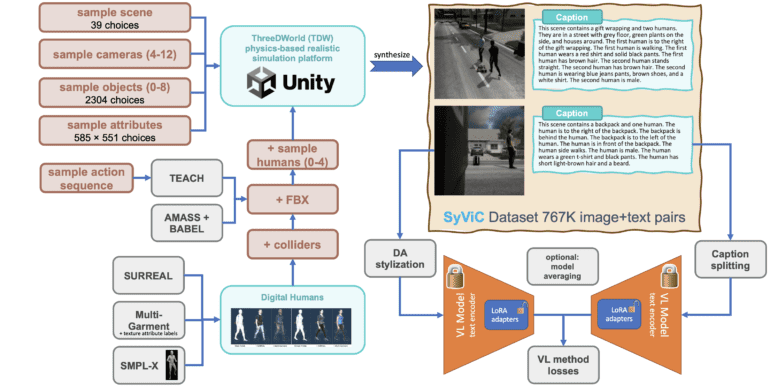
MIT researchers have pioneered a groundbreaking solution to address this inherent limitation. Their innovative approach harnesses computer-generated data to empower vision and language models, enabling them to overcome these challenges. Their methodology involves enriching both the VLC and compositional aspects of synthetic visual and textual data and subsequently fine-tuning the models to emphasize these critical elements. Moreover, the use of synthetic data offers distinct advantages – it is cost-effective, infinitely scalable, and devoid of the privacy concerns associated with real data.
However, creating synthetic data that effectively enhances VLC comprehension and compositional reasoning in models pre-trained on massive volumes of real data presents formidable technical hurdles. Unlike previous efforts in synthetic data generation, MIT’s approach involves crafting images and text descriptions that encapsulate the complex compositional elements of scenes. Additionally, they go a step further by generating synthetic videos featuring authentic 3D simulations, diverse environments, objects, human motions, and interactive elements from various camera angles.
MIT’s contribution, known as Synthetic Visual Concepts (SyViC), stands as a million-scale synthetic dataset with rich textual annotations meticulously designed to elevate VLC comprehension and compositional reasoning in vision and language models. Alongside this valuable dataset, they provide the methodology and codebase for its synthesis and potential expansion.
The results are nothing short of impressive. Through effective fine-tuning using SyViC data, MIT researchers have significantly improved the capabilities of pre-trained vision and language models without compromising their zero-shot performance. Experimental results and a comprehensive study reveal substantial enhancements, with improvements exceeding 10% in some cases. These improvements are validated across various benchmarks, including VL-Checklist, ARO, and Winoground, showcasing the effectiveness of this approach on popular models like CLIP and its derivatives, such as the cutting-edge CyCLIP.
While the potential of synthetic data to augment VLC comprehension and compositional reasoning is undeniable, MIT researchers acknowledge certain limitations in their work. The graphics simulator employed in data generation has simplified models for lighting, sensor noise, and reflectance functions compared to the real world, potentially affecting color constancy robustness. Future endeavors may require more sophisticated domain adaptation and rendering techniques to further enhance outcomes. Moreover, a more extensive exploration of scaling laws for synthetic data could unlock even greater potential.
Conclusion:
MIT’s groundbreaking use of synthetic data in advancing vision and language models represents a significant leap forward in the AI market. By enhancing VLC comprehension and compositional reasoning, this innovation opens doors to more capable AI applications, promising increased accuracy and versatility in a range of industries, from healthcare to autonomous vehicles and beyond. As the AI market continues to evolve, MIT’s pioneering work positions synthetic data as a key driver of progress, offering unprecedented potential for AI research and development.