
TL;DR:
- CLIP, a neural network by OpenAI, has been instrumental in advancing computer vision and NLP research.
- A new approach called MetaCLIP is introduced, focusing on data curation for enhanced language-image pre-training.
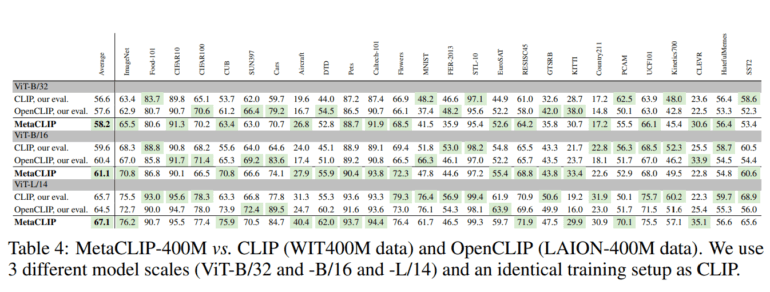
- MetaCLIP surpasses CLIP’s performance on CommonCrawl with 400M image-text pairs and zero-shot ImageNet classification using ViT models.
- The data curation process involves aligning image-text pairs with metadata, grouping texts, and sub-sampling for a balanced distribution.
- MetaCLIP doesn’t use images directly, but controls text quality and distribution, increasing chances of relevant visual content.
- The algorithm formalizes the curation process, improving scalability and reducing space complexity.
Main AI News:
The world of Artificial Intelligence has witnessed remarkable strides in recent years, particularly in the realms of Natural Language Processing (NLP) and Computer Vision. Among these innovations, CLIP, a neural network developed by OpenAI, has emerged as a groundbreaking force. Trained on an expansive dataset comprising text and image pairs, CLIP has not only propelled computer vision research but has also underpinned the capabilities of modern recognition systems and generative models. Experts contend that the key to CLIP’s success lies in its training data, and they speculate that unraveling the data curation process could pave the way for even more potent algorithms.
In a groundbreaking research endeavor, experts have endeavored to demystify CLIP’s data curation methodology and introduce the world to Metadata-Curated Language-Image Pre-training, or MetaCLIP. MetaCLIP takes raw, unstructured data and metadata gleaned from CLIP’s conceptual foundations, orchestrating a harmonious fusion. This process yields a balanced subset aligned with the metadata distribution, consistently outperforming CLIP’s original data when tested on the CommonCrawl dataset, boasting a staggering 400 million image-text pairs.
The architects of this research have meticulously adhered to the following principles in pursuit of their objectives:
- Aggregating a brand-new dataset of 400 million image-text pairs, meticulously sourced from diverse online repositories.
- Employing substring matching techniques to align image-text pairs with relevant metadata entries, effectively bridging the gap between unstructured text and structured metadata.
- Grouping all texts linked to each metadata entry into coherent lists, thus establishing a clear mapping between each entry and its corresponding textual content.
- Subjecting the associated lists to a judicious sub-sampling process, ensuring a more balanced data distribution, thereby rendering it an invaluable asset for pre-training endeavors.
- Introducing an innovative algorithm to formalize the curation process, fostering scalability and reducing space complexity.
Notably, MetaCLIP refrains from utilizing images directly in its data curation process but maintains a tight grip on the quality and distribution of textual content. The use of substring matching significantly heightens the likelihood of textual references to entities depicted in images, thereby augmenting the probability of finding congruent visual content. Moreover, the focus on balancing extends a helping hand to long-tailed entries, which often boast a richer diversity of visual content compared to their mainstream counterparts.
In rigorous experiments, the research team harnessed two data pools: one for estimating a target of 400 million image-text pairs and another for scaling the curation process. As earlier mentioned, MetaCLIP consistently outperforms CLIP when applied to the CommonCrawl dataset featuring 400 million data points. Notably, MetaCLIP even surpasses CLIP in zero-shot ImageNet classification, leveraging ViT models of varying sizes.
MetaCLIP demonstrates its prowess by achieving a remarkable 70.8% accuracy in zero-shot ImageNet classification using a ViT-B model, while CLIP manages 68.3% accuracy. Furthermore, MetaCLIP raises the bar with a 76.2% accuracy score employing a ViT-L model, while CLIP attains 75.5% accuracy. Scaling the training data to a staggering 2.5 billion image-text pairs, while adhering to the same budget and distribution, catapults MetaCLIP’s accuracy to unprecedented heights—79.2% for ViT-L and an astounding 80.5% for ViT-H. These remarkable achievements in zero-shot ImageNet classification herald a new era of possibilities in the field of AI.
Conclusion:
MetaCLIP’s breakthrough in language-image pre-training not only outperforms its predecessor CLIP, but also sets a new standard for AI capabilities. This advancement opens up exciting possibilities for businesses across various industries, enabling more accurate and efficient image-text processing, which can drive innovation, improve customer experiences, and enhance decision-making processes. As MetaCLIP continues to evolve, it has the potential to reshape markets by empowering AI-driven applications with greater intelligence and versatility. Businesses that harness the power of MetaCLIP are poised to gain a significant competitive advantage in the AI-driven landscape.