
- MiniGPT4-Video, developed by KAUST and Harvard, revolutionizes video comprehension by integrating visual and textual data.
- It outperforms traditional Large Language Models (LLMs) in decoding the complex interplay between visual scenes and accompanying text.
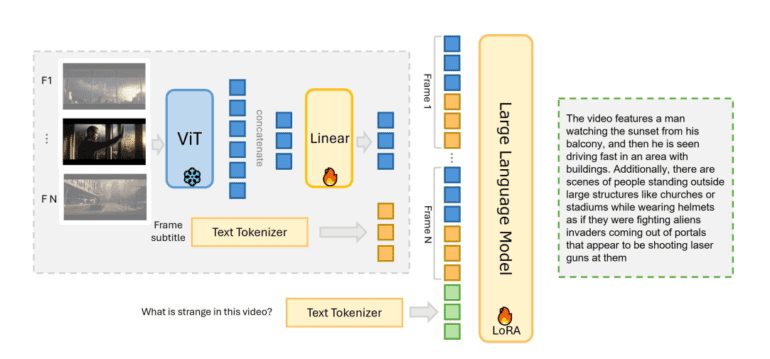
- The model’s innovative approach involves concatenating visual tokens and incorporating textual subtitles, minimizing information loss.
- MiniGPT4-Video achieves significant performance gains across various benchmarks, showcasing its superiority in multimodal video understanding.
- Utilizing subtitles as input enhances accuracy, particularly evident in benchmarks like TVQA, where performance surged from 33.9% to 54.21%.
- MiniGPT4-Video’s adaptability ensures robust comprehension across diverse video datasets, solidifying its position as a pioneering solution.
Main AI News:
KAUST and Harvard University researchers have unveiled a groundbreaking solution to the challenges of video comprehension with their latest creation, MiniGPT4-Video. In today’s fast-paced digital realm, the convergence of visual and textual data is paramount for unlocking deeper insights into video content. Traditional Large Language Models (LLMs) have excelled in textual understanding but lagged in grasping the complexities of video. MiniGPT4-Video bridges this gap with its innovative multimodal approach, setting a new standard in video understanding.
Building upon the success of its predecessor, MiniGPT-v2, which revolutionized static image analysis, MiniGPT4-Video extends its capabilities to the dynamic world of video. By seamlessly integrating visual and textual inputs, the model achieves unprecedented levels of comprehension, outperforming existing methods in decoding the intricate relationship between visual scenes and accompanying text.
Key to MiniGPT4-Video’s prowess is its novel technique for processing multimodal data. By strategically concatenating visual tokens and incorporating textual subtitles, the model minimizes information loss while maximizing comprehension. This simultaneous analysis of visual and textual elements enables MiniGPT4-Video to decode video content comprehensively, offering invaluable insights into its narrative and context.
The model’s performance speaks volumes, with significant enhancements observed across various benchmarks such as MSVD, MSRVTT, TGIF, and TVQA. Notably, MiniGPT4-Video achieved remarkable gains of 4.22%, 1.13%, 20.82%, and 13.1% on these benchmarks, respectively, underscoring its superiority in multimodal video understanding.
A standout feature of MiniGPT4-Video lies in its utilization of subtitles as an input source. This strategic integration significantly enhances accuracy, particularly evident in scenarios like the TVQA benchmark, where the model’s performance surged from 33.9% to an impressive 54.21%. This highlights the pivotal role of combining visual and textual data to unlock deeper insights into video content.
However, MiniGPT4-Video’s adaptability shines through, as evidenced by its consistent performance across diverse video datasets. Even in scenarios where textual information is less prevalent, the model’s versatility ensures robust comprehension, reaffirming its status as a pioneering solution in video understanding.
Conclusion:
The introduction of MiniGPT4-Video marks a significant milestone in the field of video understanding. Its ability to seamlessly integrate visual and textual data sets a new standard, offering invaluable insights into video content. As organizations increasingly rely on multimedia content for communication and analysis, the advancements brought forth by MiniGPT4-Video have the potential to reshape how businesses harness the power of video in various sectors, such as marketing, entertainment, and education. This innovation underscores the importance of multimodal approaches in advancing the capabilities of AI-driven solutions for video comprehension, paving the way for enhanced user experiences and deeper insights in the digital landscape.